
By: Bart Baesens, Seppe vanden Broucke
This QA first appeared in Data Science Briefings, the DataMiningApps newsletter as a “Free Tweet Consulting Experience” — where we answer a data science or analytics question of 140 characters maximum. Also want to submit your question? Just Tweet us @DataMiningApps. Want to remain anonymous? Then send us a direct message and we’ll keep all your details private. Subscribe now for free if you want to be the first to receive our articles and stay up to data on data science news, or follow us @DataMiningApps.
You asked: In fraud detection, it is often stated that the target is noisy. What is meant by that?
Our answer:
In fraud detection, the target fraud indicator is usually hard to determine since one can never be fully sure that a certain transaction (e.g. credit card fraud), claim (e.g. insurance fraud), or company (e.g. tax evasion fraud) is fraudulent. Let’s take the example of insurance fraud. If an applicant files a claim, the insurance company will perform various checks to flag the claim as suspicious or non-suspicious. When the claim is considered as suspicious, the insurance firm will first decide whether it’s worthwhile the effort to pursue the investigation. Obviously, this will also depend upon the amount of the claim, such that small amount claims are most likely not further considered, even if they are fraudulent. When the claim is considered worthwhile to investigate, the firm might start a legal procedure resulting into a court judgment and/or legal settlement flagging the claim as fraudulent or not. It is clear that also this procedure is not 100% error-proof and thus non-fraudulent claims might end up being flagged as fraudulent or vice versa.
Another example is tax evasion fraud. An often used fraud mechanism in this setting is a spider construction, as depicted in below

The key company in the middle represents the firm who is the key perpetrator of the fraud. It starts up a side company (Side Company 1) which makes revenue but deliberately does not pay its taxes and hence intentionally goes bankrupt. Upon bankruptcy, its resources (e.g. employees, machinery, equipment, buyers, suppliers, physical address, and other assets) are shifted towards a new side company (e.g. Side Company 2) which repeats the fraud behavior and thus again goes bankrupt. As such, a web of side companies evolves around the key company. It is clear that in this setting it becomes hard to distinguish a regular bankruptcy due to insolvency, from a fraudulent bankruptcy due to malicious intent. In other words, all fraudulent companies go bankrupt, but not all bankrupt companies are fraudulent. This is depicted in the figure below. While suspension is seen as a normal way of stopping a company’s activities (i.e., all debts redeemed), bankruptcy indicates that the company did not succeed to pay back all its creditors. Distinguishing between regular and fraudulent bankruptcies, is subtle and hard to establish. Hence, it can be expected that some regular bankruptcies are in fact undetected fraudulent bankruptcies.
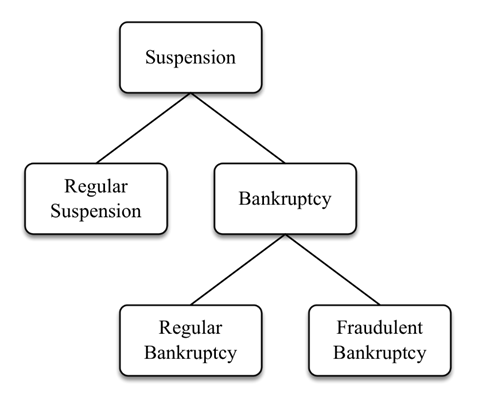
Also the intensity of the fraud when measured as an amount might be hard to determine since one has to take into account direct costs, indirect costs, reputation damage and the time value of the money (e.g. by discounting).
To summarize, in supervised fraud detection the target labels are typically not noise-free hereby complicating the analytical modeling exercise. It is thus important for analytical techniques to be able to cope with this.