
By: Bart Baesens, Seppe vanden Broucke
This QA first appeared in Data Science Briefings, the DataMiningApps newsletter. Also want to submit your question? Just Tweet us @DataMiningApps. Want to remain anonymous? Then send us a direct message and we’ll keep all your details private. Subscribe now for free if you want to be the first to receive our articles and stay up to data on data science news, or follow us @DataMiningApps.
You asked: I noted you used the Google PageRank algorithm in your Fraud Analytics work. Can you explain how Google PageRank works?
Our answer:
The ranking module for Google’s search engine is based on the PageRank algorithm introduced by Page et al in 1999 (Page L, Brin S., Motwani R., Winograd T., The PageRank citation ranking: Bringing order to the Web, Proceedings of the 7th International World Wide Web Conference, page 161-172, Brisbane, Australia, 1998). The PageRank algorithm aims to simulate surfing behavior. The below figure represents a network of web pages linking to each other. Given the figure, what is the probability that a surfer will visit web page A? Assume for now that a surfer only browses web pages by following the links on the web page s/he is currently visiting. The figure shows that web page A has three incoming links. A surfer currently visiting web page B, will visit web page A next with a probability of 20% (= 1/5). This is because web page B has 5 links to other web pages, among which web page A. Analogously, if a surfer is currently on web page C or D, there is a probability of 33.33% and 50% respectively that web page A will be visited next. The probability of visiting a web page is called the PageRank of that web page. To know the PageRank of web page A, we must know the PageRank of web page B, C and D. This is often called collective inference: the ranking of one web page depends on the ranking of other web pages; and a change in the ranking of one web page might affect the ranking of all other web pages.
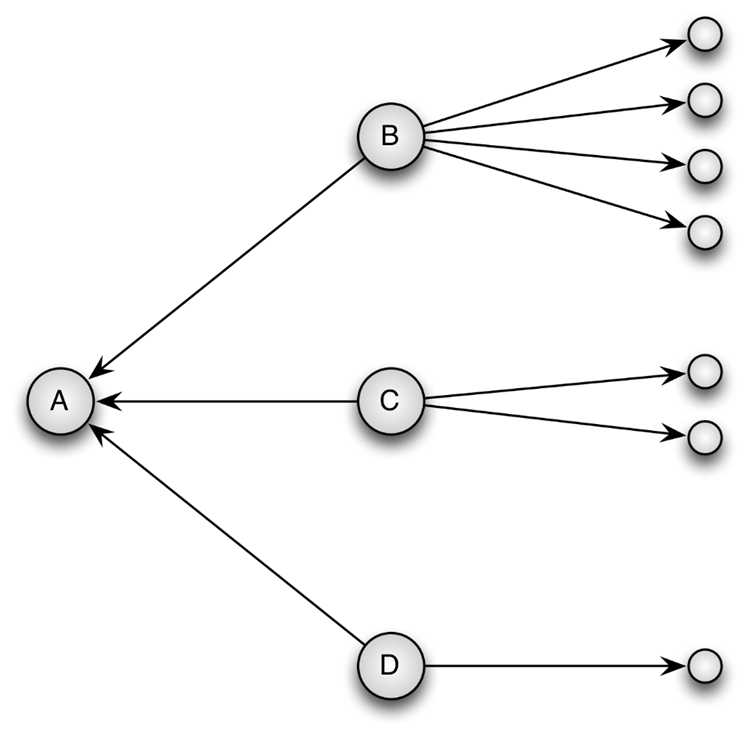
The PageRank algorithm
Specifically, the main idea is that important web pages (i.e., web pages that appear at the top of the search results) have many incoming links from other (important) web pages. Hence, the ranking of a web page depends on (a) the ranking of web pages linking towards that web page, and (b) the number of outgoing links of the linking web pages. However, visiting web pages by following a random link on the current web page is not a realistic assumption. Surfers’ behavior is typically more random: instead of following one of the links on a web page, they might also randomly visit another web page. Therefore, the PageRank algorithm includes this random surfer factor which assumes that surfers might randomly jump to another web page. With a probability of alpha the surfer will follow a link on the web page s/he is currently visiting. However, with a probability 1-alpha, the surfer visits a random other web page. The PageRank formula can then be expressed as follows:
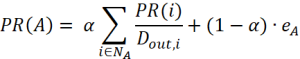
with PR(A) the PageRank of web page A, NA the pages linking to page A, Dout,i the number of outgoing links of web page i, 1-alpha the restart probability, and eA the restart value for web page A, which is often uniformly distributed among all web pages. This equation requires the ranking of the neighboring web pages. One option is to start with a random page rank value for every web page and iteratively update the PageRank scores until a predefined number of iterations is reached or a stopping criterion is met (e.g., when the change in the PageRank scores is marginal).
The above equation can be rewritten so the ranking is computed for all web pages simultaneously
![]()
with r a vector of size n containing the PageRanks of all n web pages, the column-normalized adjacency matrix of size n x n, 1-alpha the restart probability and e the restart vector. The restart vector is generally uniformly distributed among all web pages, and normalized afterwards.
We used the PageRank algorithm in our Fraud Analytics research (see, e.g., our Gotcha and APATE algorithms) to propagate the influence of fraudsters to other connected nodes in the network (e.g. a network based on credit card transactions). We found features based on Google PageRank to be highly predictive of fraud.