
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
Contributed by: Seppe vanden Broucke and Bart Baesens. This article was adopted from our Managing Model Risk book. Check out managingmodelriskbook.com to learn more.
Put simply, data leakage occurs when information is used to train the model which is not really available at the time when the model would be queried to make a prediction, as the figure below shows:
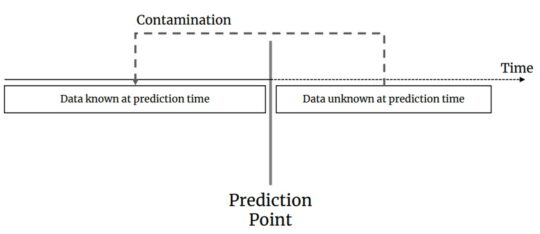
Training on contaminated data leads to overly optimistic expectations about model performance in production. More precisely, we can make a difference between feature leakage and instance leakage. Feature leakage can be caused by the inclusion of features which are too correlated to the label, either a duplicate, or a proxy. There’s typically a timing aspect involved here. As an example, consider a feature containing the number of late payments on a loan which would be included in a model which tries to predict a loan default target. Obviously, at the time when the model should make its prediction, the customer doesn’t have the loan yet, and hence the number of late payments would be zero. This sounds like a trivial mistake, but keep in mind that cases such as these can remain hidden when one is working with a large number of features, and is not checking each one of them. In fact, even after having deployed the model it might not be immediately clear that something is going wrong, for instance when the number of late payments gets imputed with zeros for all incoming cases. The model will happily provide a prediction, but will obviously under-estimate the probabilities given to instances. It can also happen that one of the features is a coded feature which combines other features and the target in some manner. For example, say we have a categorical feature with levels such as “A01X”, “B03Y”, “A05X”, etc. Now say the last character in this string would correlate with our target. Again, it is very well possible that this could remain hidden during model development, especially if the developer does not have good metadata available including a data dictionary describing the features and their levels.
Another way how feature leakage can occur is by incorporating a unique identifier in the feature set, such as a unique customer or case identifier. Again, this can cause the model to memorize these but will be useless to make predictions for unseen cases with unseen identifiers. In fact, this is an extreme form of a feature being correlated to the target, and easy to miss as the feature typically has a much higher cardinality than the target.
Feature leakage can also crop up due to a lack of snapshot-ability, i.e. it not being possible to retrieve the value of features (and the correct state of an instance) for a past point in time. Very often, this is due to implementation design choices where e.g. database records get updated over time but no lineage or audit trail is kept of the changes. This can be extremely easy to miss in case most features are entered before the prediction point (and are not changed), and only a few of them are changed after the prediction point. Again, without a clear view on the underlying business process and without good metadata, this can lead to issues down the line, even after a model is deployed.
Instance leakage is caused by improper sharing of information between rows of data. This can be due, for instance, to premature preprocessing and featurization, e.g. performing featurization or preprocessing steps before a train/test split is performed. Very often this looks very innocent, like imputing missing values in a feature with its mean or median value, or by transforming a feature by standardizing it so it falls between zero and one, or by applying a Principal Component Analysis (PCA) in order to reduce the number of dimensions. If any of these is done before you have set aside a holdout test set, there is data leakage going on. The reason for this is that any of these things just mentioned already involves learning something over multiple instances. When deciding what to impute missing values with, extracting a mean is learning something. When you do so on the whole data set, you’re effectively leaking the test set feature distribution into the training set. The proper approach here is to take the mean of the training set and store that value as part of the model prediction pipeline—it is something you have learned. When new instances arrive (from the test set or even later once the model is running in production), you should re-utilize the same stored value to impute with.
Sometimes, when hearing this, people will argue that this doesn’t work in volatile settings. For example, what if the mean of a feature changes every month? Then obviously sticking with that mean you derived in the training set will lead to bad results. This is true, but is in fact exactly the reason why we set up our train and test split in this way. If a feature is indeed volatile, we will see the problem when testing the model. Secondly, even if you would use the current mean to impute with, remember that the non-missing feature values will all have shifted as well, though your model is still working based on the distribution it observed back when it was trained. Later on, we will return to this issue and see how it can be avoided by setting up proper validation and monitoring. For now, the answer is that, during development, data leakage should be avoided at all costs.
Apart from this, instance leakage can also be caused by duplicated or very similar instances which end up being shared between the train and test set. For example, they might contain the same observations but which were measured at different moments in time, or might be images of the same underlying object or subject in the case of a deep learning model, but taken from slightly different angles or some time apart.
To provide a famous example of this, we can mention the story about a 2017 paper by Andrew Ng and his team on Pneumonia Detection on Chest X-Rays (Rajpurkar, P., Irvin, J., Zhu, K., Yang, B., Mehta, H., Duan, T. et al.). After publishing the first version of the paper on arXiv, Nick Roberts responded in a Tweet and asked if the authors were concerned about the fact that even although 20% of the data was set aside as a holdout, the data set used contains 112,120 frontal-view X-ray images of 30,805 unique patients so that multiple instances will hence be belonging to the same patient, and carry the same label. When a random splitting is applied, it is clear that data leakage will occur. The authors fixed the mistake and prepared an updated version of the paper, but if a top deep learning researcher can be caught off-guard by data leakage, it can happen anywhere and to anyone.
Instance leakage can also be the result of having applied resampling techniques (such as oversampling or undersampling) on the complete data set rather than on the train set only, which will again lead to the same duplicated instance showing up in the train and test set.
As such, keep the following in mind to avoid data leakage: split the holdout test set immediately and do not preprocess it in any way before you’re ready to evaluate your final model. If possible, also try to get a hold of a data dictionary and understand the meaning of every column, as well as unusual values or codes. For every feature, confirm that this feature will be available at prediction time. Perform preprocessing on the training set and then freeze its parameters. Make sure that instances are not showing up multiple times (and could show up both in train and test). Finally, check feature importance scores and use interpretability techniques to assess whether the top contributing features actually make sense.
Finally, we often get the question that if we need to be so strict in terms of how we perform the train/test split, whether the same separation principle should be applied in the case where cross-validation is performed. The short answer is that yes, ideally, you would. Since it is typically hard to correctly set this up from a technical perspective, the choice is sometimes made to e.g. preprocess and featurize the complete train set and not do it separately for each fold. This is somewhat acceptable, as cross-validation is mainly used for model tuning and selection. If we were sloppy somewhere in the development process, we still have the unspoiled test set to show us the errors. Instead of trying to find a model which simply performs best on the test set, your goal should be to construct a test set which best reflects the changes that might arise in your data as possible, given what you know today.