
In close collaboration with prof. Vanthienen and prof. De Weerdt we do research on Process Analytics & Mining.
Most traditional machine learning techniques assume that input data are provided in the form of a flat, tabular structure, with columns describing variables (explanatory and target) and rows corresponding with data instances. Process analytics related techniques aim to go one step further and deal with data describing a flow, traces or sequences of activities. The need for such techniques becomes especially apparent in a business process setting. The field of “process mining” has sprung up around a decade ago which aims to discover and analyze business processes as they happen in the organization. As such, our research team currently focuses on the following topics in process analytics:
- Applying process analytics to marketing analytics and customer-centric scenarios such as customer journey mapping, dynamic segmentation, web log analysis
- Developing predictive analytics techniques towards process-oriented contexts, e.g. lead-time prediction, executor recommendation systems
- Expanding the field of process analytics to the broader area of log analytics, including various sorts of operational logs
- Industry applications of process mining: telecom industry, banking industry, government
- New process quality evaluation metrics for robust conformance checking
- Clustering techniques to untangle and explain complex process models
- The use of artificially generated negative events for the discovery and conformance analysis of process models from event logs
- Assessment of currently available process discovery evaluation metrics via the development of strong benchmarking tools
Process Mining and Intelligence
Today’s organizations employ a wide range of information support systems to support their business processes. Such support systems record and log an abundance of data, containing a variety of events that can be linked back to the occurrence of a task in an originating business process. The field of process mining starts from these event logs as the cornerstone of analysis and aims to derive knowledge to model, improve and extend operational processes “as they happen” in the organization. As such, process mining can be situated at the intersection of the fields of Business Process Management (BPM) and data mining.
Process Discovery and Identification
Consider for instance the following event log:
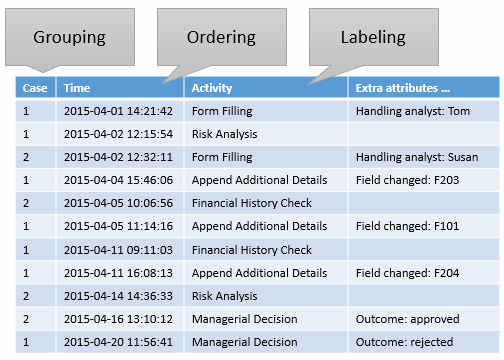
A simple event log for a credit application process.
Notice that the data table provided does not describe a flat structure, but instead contains the following characteristics:
- A grouping factor, relating multiple rows to one another (here: the case identifier)
- An ordering, ordering the rows globally or within a group (here: a timestamp)
- A labeling, a method to assign labels (i.e., a “name”) to each row (here: the activity name)
A first analysis task within the realm of process mining is that of process discovery: extracting a model which represents the real-life situation:
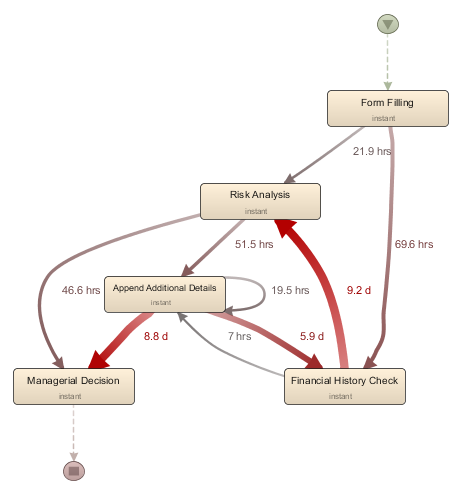
A process model visualising the flows between activities as extracted from the event log.
Doing so can help to answer questions such as: “what does the real process look like?”, “what are the common pathways?”, “where are bottlenecks occurring?”, “how do people work together?”, “how do case and activity properties affect the duration or flow?”. The challenge here is to come up with appropriate techniques to make understandable but correct abstractions of the activity flows contained in the event log, as well as highlight important information at a glance, e.g. by means of clustering, filtering, or comparison techniques.
Conformance Checking
In some cases, end-users might desire to compare the real-life behavior as described in an event log with a prescriptive model, or simply a set of rules which need to be followed. This can help to answer questions such as “where does the reality deviate from the model?”, “which rules are commonly broken?”, “which SLA’s are not met?” and “why does reality deviate from prescribed rules?”.
Tightening the Link with Data Mining
In most cases, analysts answer the questions mentioned above by means of exploratory, visually-driven analysis. However, we argue that the link between process mining and data mining should be tightened, and are working on research tracks around this topic. This becomes especially important when models become too complex to be inspected visually. In some cases, we have seen analysts making conclusions based on a filtering step (show me the top 10 employees working on cases taking longer than n days) without confirming this globally (what about the top 10 employees for cases less than n days?).
As such, we are currently working on answering questions such as: “how does this model evolve over time, what has changed?”, “what are the significant differences between these two models?”, “can we predict the running time or complexity of an incoming case based on the past and its attributes?”. Especially the latter concept of predictive process mining is an avenue we are currently pursuing.
Customer Journeys and Other “Flows”
 Recently, there has been a rising interest in applying process mining techniques in less-internal-process-oriented contexts such as customer journey mapping and dynamic customer segmentation exercises. In our research group, a novel approach was developed towards enabling the exploratory understanding of the dynamics inherent in the capture of customers’ data at different points in time (publication: “A dynamic understanding of customer behavior processes based on clustering and sequence mining”). Our methodology combines state-of-art data mining clustering techniques with a tuned sequence mining method to discover prominent customer behavior trajectories in data bases, which represent the “behavior process” as it is followed by particular groups of customers.
Recently, there has been a rising interest in applying process mining techniques in less-internal-process-oriented contexts such as customer journey mapping and dynamic customer segmentation exercises. In our research group, a novel approach was developed towards enabling the exploratory understanding of the dynamics inherent in the capture of customers’ data at different points in time (publication: “A dynamic understanding of customer behavior processes based on clustering and sequence mining”). Our methodology combines state-of-art data mining clustering techniques with a tuned sequence mining method to discover prominent customer behavior trajectories in data bases, which represent the “behavior process” as it is followed by particular groups of customers.
The framework was applied to a real-life case of an event organizer, where it was shown how behavior trajectories can help to explain consumer decisions and to improve business processes that are influenced by customer actions.
In addition to focussing on customer journeys and dynamic segmentations, we are also exploring how process analytics related techniques can be applied to other types of data “flows”. Web interaction logs in particular (e.g. web server logs) form an interesting opportunity in this context.
Everybody Logs: Towards Log Analytics
 Recall that process mining techniques start from a so called event log to perform their analysis tasks. The following two trends can be observed over the past few years: first, as mentioned above, there is a growing interest to apply process mining techniques in contexts outside of traditional BPM. Second, we observe that data logging practices are rising exponentially. Think for example about audit trails, security logs, application logs, server logs, tracking logs, etc. as emitted by network devices, apps, phones, operating systems, and all manner of intelligent devices connect to tomorrow’s Internet of Things.
Recall that process mining techniques start from a so called event log to perform their analysis tasks. The following two trends can be observed over the past few years: first, as mentioned above, there is a growing interest to apply process mining techniques in contexts outside of traditional BPM. Second, we observe that data logging practices are rising exponentially. Think for example about audit trails, security logs, application logs, server logs, tracking logs, etc. as emitted by network devices, apps, phones, operating systems, and all manner of intelligent devices connect to tomorrow’s Internet of Things.
As such, we predict that in the years to come, process mining, flow analytics, log analytics, sequence mining and of course predictive data mining will all continue to grow towards each other. This will naturally come with a number of new challenges which will need to be addressed by practitioners and researchers. We think for instance about:
- Methods to combine various log streams into one and finding correlations and matches amongst them
- Methods to extract structure (groups, ordering, labels) from unstructured logs
- This includes techniques such as pattern recognition, normalization (converting log messages to similar formats), correlation analysis (finding all messages related to the same source cause) and querying tools
- Combining predictive machine learning techniques to predict message classes or to develop ignorance models which are able to filter out uninteresting messages
Further Reading
processmining.be
See www.processmining.be for more information about process mining related research projects from LIRIS, including various software downloads and implementations you can use right away.
Video
- A mini lecture on process analytics by dr. Seppe vanden Broucke: YouTube
PhD Theses
- Download PhD thesis by Jochen De Weerdt (2012): Business Process Discovery: New Techniques and Applications
- Download PhD thesis by Seppe vanden Broucke (2014): Advances in Process Mining: Artificial Negative Events and Other Techniques
Selected Publications
- Ponce de Leon H., Nardelli L., Carmona J., vanden Broucke S. (2017). Incorporating negative information to process discovery of complex systems. Information Sciences.
- vanden Broucke S., De Weerdt J. (2017). Fodina: a robust and flexible heuristic process discovery technique. Decision Support Systems, 100, 109-118.
- De Koninck P., De Weerdt J., vanden Broucke S. (2017). Explaining clusterings of process instances. Data Mining and Knowledge Discovery, 31 (3), 774-808.
- vanden Broucke, S., De Weerdt, J., Vanthienen, J., Baesens, B. (2014). Determining process model precision and generalization with weighted artificial negative events. IEEE Transactions on Knowledge and Data Engineering, 26 (8), 1877-1889.
- Seret, A., vanden Broucke, S., Baesens, B., Vanthienen, J. (2014). A dynamic understanding of customer behavior processes based on clustering and sequence mining. Expert Systems with Applications, 41 (10), 4648-4657.
- De Weerdt, J., De Backer, M., Vanthienen, J., Baesens, B. (2012). A multi-dimensional quality assessment of state-of-the-art process discovery algorithms using real-life event logs. Information Systems, 37 (7), 654-676.
- vanden Broucke, S., Munoz-Gama, J., Carmona, J., Baesens, B., Vanthienen, J. (2014). Event-based real-time decomposed conformance analysis. On the Move Federated Conferences & Workshops: Vol. accepted. International Conference on Cooperative Information Systems (CoopIS 2014). Amantea, Calabria (Italy), 27-31 October 2014 Springer.
- vanden Broucke, S., Vanthienen, J., Baesens, B. (2014). Declarative process discovery with evolutionary computing. 2014 IEEE Congress on Evolutionary Computation Proceedings. 2014 IEEE. Beijing (China), 6-11 July 2014 (pp. 2412-2419) IEEE.
- De Weerdt, J., vanden Broucke, S., Vanthienen, J., Baesens, B. (2012). Active trace clustering for improved process discovery. IEEE Transactions on Knowledge and Data Engineering, accepted.
- Goedertier, S., De Weerdt, J., Martens, D., Vanthienen, J., Baesens, B. (2011). Process discovery in event logs: an application in the telecom industry. Applied Soft Computing, 11 (2), 1697-1710.
- Goedertier, S., Martens, D., Vanthienen, J., Baesens, B. (2009). Robust process discovery with artificial negative events. Journal of Machine Learning Research, 10, 1305-1340.
- vanden Broucke, S., De Weerdt, J., Vanthienen, J., Baesens, B. (2013). A comprehensive benchmarking framework (CoBeFra) for conformance analysis between procedural process models and event logs in ProM. Proceedings of the IEEE Symposium on Computational Intelligence and Data Mining, CIDM 2013, part of the IEEE Symposium Series on Computational Intelligence 2013, SSCI 2013: vol. accepted. IEEE Symposium on Computational Intelligence and Data Mining (CIDM 2013). Singapore, 16-19 April 2013.
- Caron, F., vanden Broucke, S., Vanthienen, J., Baesens, B. (2012). On the distinction between truthful, invisible, false and unobserved events. Proceedings of the 18th Americas Conference on Information Systems: vol. accepted. Americas Conference on Information Systems. Seattle, Washington (US), 9-12 August 2012.
- De Weerdt, J., vanden Broucke, S., Vanthienen, J., Baesens, B. (2012). Leveraging process discovery with trace clustering and text mining for intelligent analysis of incident management processes. Evolutionary Computation (CEC), 2012 IEEE Congress on. Congress on Evolutionary Computation (CEC), 2012 IEEE. Brisbane (Australia), 10-15 June 2012 (pp. 1-8).
- De Weerdt, J., De Backer, M., Vanthienen, J., Baesens, B. (2011). A robust F-measure for evaluating discovered process models. CIDM. IEEE Symposium Series in Computational Intelligence 2011 (SSCI 2011). Paris (France), 11-15 April 2011 (pp. 148-155) IEEE.