
Contributed by: Jasmien Lismont, Bart Baesens
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
Data scientists are always craving for more data to analyze, to apply new techniques on or to discover new insights from. But our society is also worrying more and more about privacy. Next year, a new European privacy regulation will be implemented [1] which will impact how companies collect, store and use data. Not only in-house privacy and security departments are as such affected, but it is time that also data scientists themselves take on responsibility. However, datasets which contain a lot of attributes are hard to truly anonymize. Even though certain values are anonymized or only partly specified, they can be inferred from the high number of attributes remaining or by joining datasets [2]. In extension, de-anonymization techniques for sparse data where limited upfront knowledge is available, are being developed [3] leading to additional concerns. On the other hand, analysts are worried about data and information loss due to profound anonymization which leads to a decrease in utility for analysis [4]. Although different research streams on this theme exist, such as anonymization techniques, differential privacy frameworks, user consent; this article will focus on a few solutions for the application of analytics techniques themselves which balance privacy and utility.
Solution 1: consumer networks
Recently Provost and his colleagues won the ISR best paper award with their paper on targeting for mobile advertisement by applying a privacy-friendly data analytics technique [5]. They’ve created a geosimilarity network where mobile devices are linked to each other if they were active on the same location, see Figure 1. This technique doesn’t require to store actual location data since knowing which users are similar to users of interest is sufficient. For example, a company might be interested in placing ads for users similar to a known customer. As such, the researchers anonymize both device and location identifiers. Similarly, in another work [6], a network is built of audiences suitable for brand advertising. Data on visitations to social network pages is used without actually storing browser identifiers or content of the pages. In both examples, the proximity of a user to an existing user of interest is enough to target (or not target) him. As such, the underlying data doesn’t need to be collected and stored anymore.
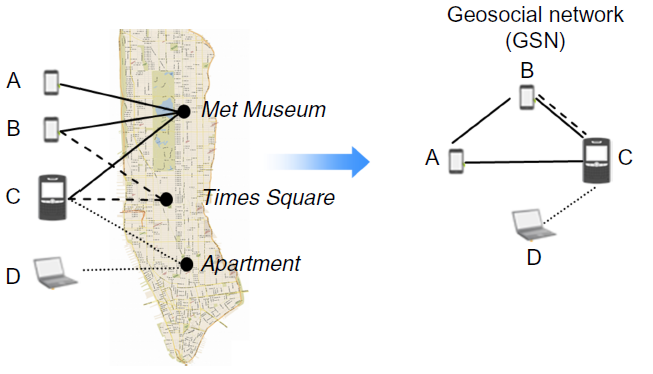
Figure 1: Example geosimilarity network of devices [5]
Solution 2: encrypted association rule sharing
Another techniques focuses on the sharing of association rules among companies [7]. There can be several reasons why this might be useful. As such, one might want to discover which rules hold universally, across companies. However, companies might be reluctant to share their rules with other parties. Therefore, this technique was developed where companies encrypt their own rule using commutative encryption. This encryption tool allows for comparison of two items without revealing their content.
Solution 3: face recognition
The following proposed technique [8] assumes two separate parties of which one has a face image and the other has access to a database of facial templates. However, both parties don’t want to share their data. The technique applies the Eigenface recognition algorithm such that the images can be compared without data leakage. For this purpose they use a cryptographic protocol for comparing encrypted values as illustrated in Figure 2. The two parties jointly run the recognition algorithm. The one with the face image starts by obtaining the necessary basis of the face space and feature vectors of the face. The other party provides an encrypted face image and learns whether this image matches the feature vectors of the first party. Researchers prove that a high reliability (96% correct classification rate) and feasibility of practical implementation are achieved.
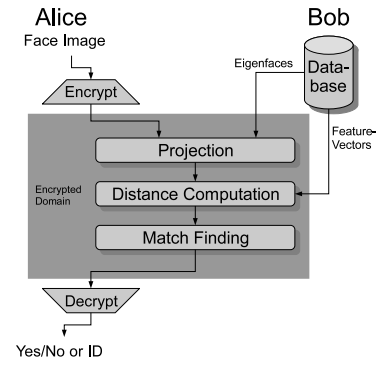
Figure 2: Privacy-preserving face recognition [8]
Solution 4: recommender systems
McSherry and Mironov [9] have developed a privacy-friendly recommendation system and applied it on the Netflix Prize dataset. Their technique enforces privacy as a property of the computation itself by making modification to the algorithm. For this purpose they add noise to the movie and user effects. As such, noise is added to the global average and count of the number of ratings and to the averages and counts per movie. Consecutively, the authors construct a stabilized per-movie average rating by introducing a fictitious global ratings factor. These averages can now be used in the final algorithm with limited loss in quality because they are able to subtract the corresponding averages of every rating to remove these per-movie global effects. Similarly, user effects are calculated. As such, they are able to introduce a privacy-aware recommender system.
We can conclude that although most data analytics techniques don’t explicitly take privacy into account, there is potential to create more privacy-friendly techniques. This can be done at different levels, at the data collection level, by anonymizing data entries, by encrypting datasets and results before comparison, and in the algorithms themselves. Both new legal regulations and user sensitivity towards their privacy are driving data scientists to take this aspect more into account.
References:
- European commission on protection of personal data. Available at http://ec.europa.eu/justice/data-protection/ and last updated on November 24, 2016.
- Aggarwal, C.C. (2005). On k-Anonymity and the Curse of Dimensionality. In: Proceedings of the 31st VLDB Conference, Trondheim, Norway, pages: 901-909. http://www.vldb2005.org/program/paper/fri/p901-aggarwal.pdf.
- Narayanan, A. and Shmatikov, V. (2008). Robust De-anonymization of Large Sparse Datasets. In: 2008 IEEE Symposium on Security and Privacy (S&P 2008), 18-21 May 2008, Oakland, California, USA, pages 111-125. http://dx.doi.org/10.1109/SP.2008.33.
- Brickell, J., and Shmatikov, V. (2008). The Cost of Privacy: Destruction of Data-Mining Utility in Anonymized Data Publishing. In: Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, Nevada, USA, August 24-27, 2008, pages 70-78. http://doi.acm.org/10.1145/1401890.1401904.
- Provost, F., Martens, D., and Murray, A. (2015). Finding Similar Mobile Consumers with a Privacy-Friendly Geosocial Design. Information Systems Research 26(2): 243-265. http://dx.doi.org/10.1287/isre.2015.0576.
- Provost, F., Dalessandro, B., Hook, R., Zhang, X., and Murray, A. (2009). Audience Selection For On-line Brand Advertising: Privacy-friendly Social Network Targeting. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, June 28 – July 1, 2009, pages 707-716. http://doi.acm.org/10.1145/1557019.1557098.
- Kantarcioglu, M., and Clifton, C. (2004). Privacy-Preserving Distributed Mining of Association Rules on Horizontally Partitioned Data. IEEE Transactions on Knowledge and Data Engineering 16(9): 1026-1037. http://dx.doi.org/10.1109/TKDE.2004.45.
- Erkin, Z., Franz, M., Guajardo, J., Katzenbeisser, S., Lagendijk, I., and Toft, T. (2009). Privacy-Preserving Face Recognition. In: Proceedings of Privacy Enhancing Technologies, 9th International Symposium, PETS 2009, Seattle, WA, USA, August 5-7, 2009, pages 235-253. http://dx.doi.org/10.1007/978-3-642-03168-7_14.
- McSherry, F., and Mironov, I. (2009). Differentially private recommender systems: Building privacy into the Netflix prize contenders. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, June 28 – July 1, 2009, pages 627-636. http://doi.acm.org/10.1145/1557019.1557090.