
With a quick hands-on introduction with 🤗Transformers and 🦜🔗LangChain
Contributed by Prof. dr. Seppe vanden Broucke and Prof. dr. Bart Baesens
By now, everyone has heard about ChatGPT, but over the past few months, a whole ecosystem of models, tools, libraries, APIs and products has developed at a rapid pace. Why is the 🤗 emoji showing up all over the place? What is prompt chaining ? What are these Alpaca, LLaMA, but also Vicuna and RedPajama models and what makes them different from what OpenAI is offering? In this article, we take you through a tour of the latest developments in the space of large language models and will play around with our own language model – no API required – using 🤗Transformers and 🦜🔗LangChain.
It all started with Transformers
We’ve come a long way since the early days of deep learning on text. From recurrent neural networks to sequence-to-sequence models, adding attention on top of those, and then coming to the realization that “attention is all you need” [1] and we could do without recurrency. BERT, GPT-2, GPT-3: they have led to a whole family of transformer-based models:
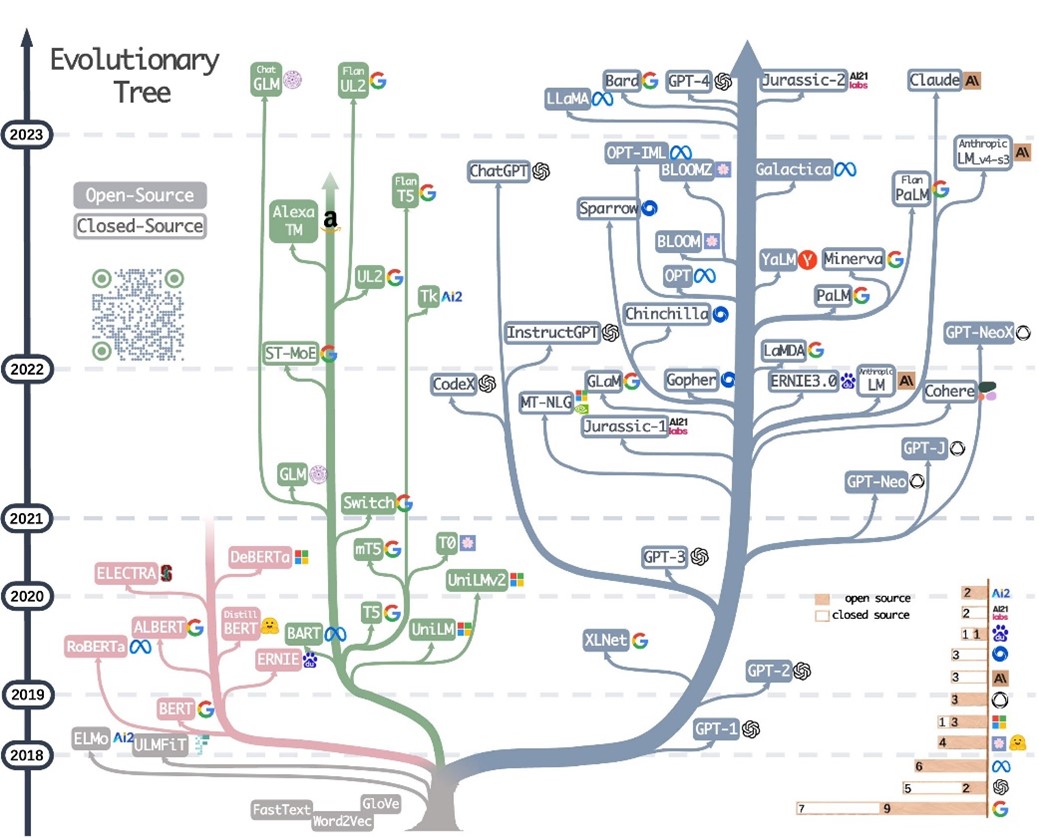
Click to view full size. Source: https://github.com/Mooler0410/LLMsPracticalGuide.
Over the years, these models have been getting larger, improved their tokenization mechanisms, used more training data, and changed up positional encoding strategies. Already around 2020, OpenAI was one of the early providers of a foundational language model in the form of GPT-3, a typical generative text-completion model.
From text completion to dialogue
With the announcement of ChatGPT at the end of last year, however, a lot of things changed [2]. OpenAI had already been experimenting with InstructGPT, an alignment strategy to have models adhere better to the intention of a prompt: think “reply to” rather than “complete” this text. E.g. compare the output of GPT-3 versus InstructGPT [3]:
Prompt: Explain the moon landing to a 6 year old in a few sentences.
GPT-3: Explain the theory of gravity to a 6 year old. Explain the theory of relativity to a 6 year old in a few sentences. Explain the big bang theory to a 6 year old. Explain evolution to a 6 year old.
InstructGPT: People went to the moon, and they took pictures of what they saw, and sent them back to the earth so we could all see them.
It’s clear that InstructGPT is much more “conversational”. Another important point was to avoid models being easily pursued towards generating toxic or harmful text. To do so, OpenAI used a technique called reinforcement learning from human feedback (RLHF):
“[…] GPT-3 […]can be coaxed to perform natural language tasks using carefully engineered text prompts. But these models can also generate outputs that are untruthful, toxic, or reflect harmful sentiments. This is in part because GPT-3 is trained to predict the next word on a large dataset of Internet text, […]. In other words, these models aren’t aligned with their users.
“To make our models safer, […], we use an existing technique called reinforcement learning from human feedback (RLHF). On prompts submitted by our customers to the API, our labelers provide demonstrations of the desired model behavior, and rank several outputs from our models. We then use this data to fine-tune GPT-3.
“The resulting InstructGPT models are much better at following instructions than GPT-3. They also make up facts less often, and show small decreases in toxic output generation.”
ChatGPT is a sibling model to InstructGPT which uses the same RLHF method. The main difference lies in the data collection: an initial model was trained using human AI trainers which provided conversations in which they played both sides: a human end user and an AI assistant. During training, RLHF in the form of PPO was used:
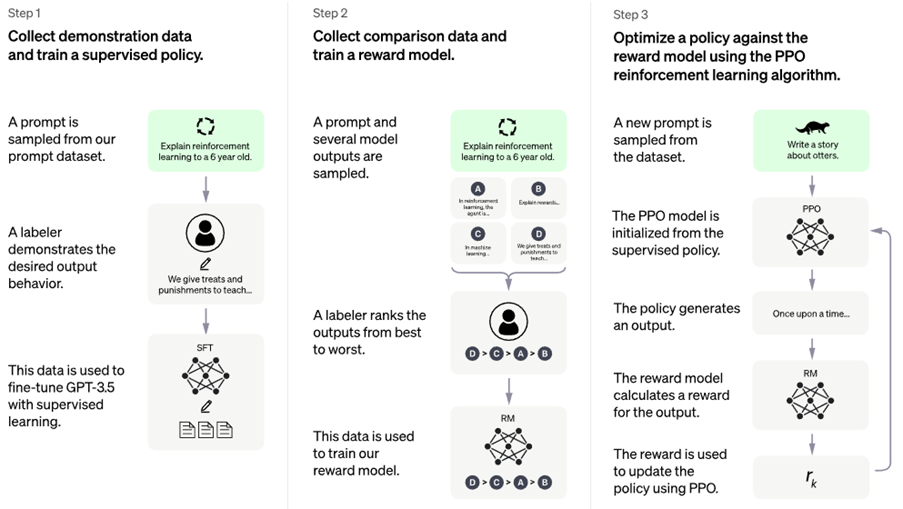
Click to view full size. Source: https://openai.com/blog/chatgpt.
LLMs explode
The rapid pace at which ChatGPT was able to obtain users, the speed by which GPT-4 was released, Microsoft’s partnership with OpenAI and the “code red” panic going on at Google all made clear that a new era in language models had arrived. During the time that followed, a couple of trends and topics started to appear:
- Worries around AI alignment: how close are we to true general artificial intelligence? Should we limit AI development? Should we regulate AI development? This is still a heated debate.
- Internet-capable language models. See the integration with Bing or the just announced integration with Windows: agents that can access real-time search results or interact with programs
- Lots of prompt engineering: from trying to coerce ChatGPT into doing naughty things to all sorts of relevant use cases. The job title of “prompt engineer” (or: AI whisperer) already appeared in the years prior but went into full hype mode
- Multi-modal models, which can take in text, but also images (and perhaps audio, video) and can also output in those formats. Still a bit tacked-on for the most part but this is sure to happen full enough (many see byte-level transformers, just as the recently announced MegaByte by Meta [4] as a way to reach this)
A lot of established tasks are disrupted. Need to write a low-effort email? Ask ChatGPT to do it. Need to write an article? Use ChatGPT as a starting point. Companies are building software around it (and Twitter is full of “10 prompts to save you 25 hours a day” spam). Academics start asking questions to PhD students spending weeks to set up a pipeline using NLTK or Spacy: why not just ask ChatGPT?
From prompt to chain
Very quickly, people started to figure out that the standard prompt-reply mechanism is not always sufficient or too high-effort in order to reach good results. We might not have general AI yet, but we do have a universal interface in the form of a text box: the prompt. As such, we start playing around with it. We try to force ChatGPT to provide an answer formatted as JSON so that we can use it downstream in our programs. People notice ChatGPT makes mistakes but can also correct them when asked “Are you sure?” As such, the first forms of chains start to arrive: feedback previous replies to the model with the question whether it contains any mistakes or how to answer can be improved (so called “chain of thought” prompting). Other chains look at creating a hierarchical approach: first ask to output a summarized action plan with short bullet points, then ask the model again for each model separately. Combined with mechanisms to execute code, this brings a somewhat higher degree of agency and autonomy to these models.
This brings us to the LangChain library: a framework for developing applications powered by language models. Since its inception, it has grown rapidly to include integrations with all sorts of model API’s and backends, ways to construct prompts, methods to persist state between calls to a model, and mechanisms to construct chains, and agents: chains in which an LLM, given a high-level directive and a set of tools, repeatedly decides an action, executes the action and observes the outcome until the directive is complete. It has been one of the key drivers behind autonomous agents, agent simulations, chatbots, question-answering tools, summarization tools and many more applications which are built on top of large language models.
As an example, take a look at privateGPT [5]: a repository where you can use an LLM to ask questions about your documents without requiring an Internet connection or subscription at all. Many of such tools use a combination of the following:
- An LLM model to provide a conversational LLM – often from the Llama family
- A “SentenceTransformers” embedding model to embed sentences from documents and provide quick lookup
- LangChain to glue it all together
We’ll take LangChain for a spin, but we first need to talk about where we get our models from.
🦙 or 🤗?
The GPT models created by OpenAI are not open-source, meaning that the weights are not public. After the release of ChatGPT, and whilst Google was working on Bard (itself a continuation of PaLM-E), Meta too announced that it was working on its own language model: LLaMa, which was not released publicly although people could request access to use it. According to Meta, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA65B is competitive with the best models: Chinchilla-70B (DeepMind) and PaLM-540B (Google).
One week after its release, however, the weights of the model were leaked online, albeit in a rather raw format, making it hard to run on commodity hardware. The weights also required further fine tuning (through e.g. RLHF), which would cost millions for normal users. However, this didn’t keep people and researchers from trying. Very soon after the leak, Stanford introduces Alpaca [6]: a fine-tuned model based on LLaMA where they used another – already aligned – model (Da-Vinci-003 from OpenAI, which was built on InstructGPT) to generate instruction-following examples. The generation cost was only $500, with the actual training only costing about $100.
Soon after this, another team proposes Vicuna [7], also built on top of LLaMa, which is able to reach near ChatGPT level performance whilst only having costed $300 (and only using 7B or 13B parameters, way less than ChatGPT). Here, the model was trained using approximately 70K user-shared conversations.
Another key element to reduce the cost required for the fine tuning of these models was LoRA: Low-Rank Adaptation of Large Language Models [8]. This seminal work proposes a mechanism to decompose weight changes into a lower rank representation. When the internal Google Document “We Have No Moat, And Neither Does OpenAI” [9] was leaked a month earlier, Google themselves admit to be surprised by the efficiency of models coming from the open source community, both in terms of fine tuning costs and parameters:
“While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months.
“In both cases, low-cost public involvement was enabled by a vastly cheaper mechanism for fine tuning called low rank adaptation, or LoRA, combined with a significant breakthrough in scale (latent diffusion for image synthesis, Chinchilla for LLMs).”
(Though to provide a counter perspective, recent work has also stated that these open source models are still far off from their proprietary counterparts: [10].)
Still, even with these fine tuned models, the cost of deploying them could still be high. Inference can be done on a commodity-GPU, yes, but setting up a large-scale infrastructure would still be costly, let alone the possibility to have a model run locally on, say, a smartphone. Enter LLama.ccp: an LLM in pure C/C+. Together with 4-bit quantization (an optimization strategy that converts 32-bit floating-point numbers such as weights and activations to the nearest lower-bit fixed-point numbers) and optimized memory management, people have gotten LLaMA models to run on Raspberry Pi’s (slowly), smartphones and laptops.
One remaining issue is that this whole LLaMA family of models are ultimately based on leaked weights, the legality of which is a bit of a grey area. The LLaMa architecture itself is licensed under GNU 3.0, a strong copyleft license, whereas Alpaca comes with similar restrictions. As such, commercial use of such models is problematic. Hence, some projects have set upon the difficult task to create a completely trained from scratch LLM, with a permissive license, e.g. OpenLLaMA, RedPajama [11] and Pythia [12]. Many of these come with a more permissive Apache license, though will often still impose use limitations.
As such, when choosing a model, a lot of considerations need to be kept in mind. Are you developing a tool to perform research with, to use privately, or to use commercially? Do you want to keep your data and prompts local, or is it fine to use e.g. OpenAI’s API? Does the model allow to be used in your use case? What was the data used to both train and fine tune the model? How large can the model be with regards to your setup?
Model development is also going extremely fast at this moment. If you check out the OpenLLM leaderboard [13] you will see that (at the time of writing), Falcon has surpassed the LLaMA family of models [14], when using the 40B model.
Let’s get coding
Let us now try out setting up our own LLM. We’re going to follow a similar style as privateGPT here, and will not make use of API-offered models. First, working in a new Python environment, we need to install PyTorch. We’ll work using the GPU on CUDA 11.7, but you can check the PyTorch website to find detailed installation instructions:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
Next, we install the 🤗Transformers library:
pip install transformers
And LangChain:
pip install langchain
We also need some additional packages:
pip install huggingface_hub pip install unstructured pip install sentence_transformers pip install docarray
Let’s talk a bit about 🤗, i.e. 🤗Hugging Face. 🤗Hugging Face is an organization and community that started mainly as a repository to host pretrained models, but since then has grown to include data sets, development spaces, and support libraries such as the 🤗Transformers library. With this, you can easily load in a model from the Hugging Face hub and get started on an AI task without bare-metal PyTorch coding. E.g. say you’re interested in depth estimation and browse the relevant category, after selecting a model like this one, you get a clear description of it, in which formats the weights are stored, tasks it supports, and instructions how to use it. Other models such as this one allow you to experiment with it directly in the browser. 🤗Hugging Face has been instrumental in the adoption and distribution of AI, and many large companies are using it.
Let’s use the 🤗Transformers library to play around with a large language model:
from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "togethercomputer/RedPajama-INCITE-Chat-3B-v1" model = AutoModelForCausalLM.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)
Note: we’re using the RedPajama-INCITE-Chat-3B-v1 model here as it has relatively good performance with only 3B parameters, though it is a good idea to experiment with newer larger models (e.g. tiiuae/falcon-7b-instruct or even tiiuae/falcon-40b-instruct) if you can. If your machine can’t handle 1B parameters, you can also use a smaller model (though the text generation will be worse).
We can then immediately prompt it:
prompt = "In this newsletter, we will introduce how to" input_ids = tokenizer(prompt, return_tensors="pt").input_ids tokens = model.generate(input_ids) tokenizer.decode(tokens[0]) Output: 'In this newsletter, we will introduce how to use the new features of the latest version of the popular'
You see that the result contains a small piece of completed text. (You can ignore the warnings that appear.)
What happens if we run the same prompt again? We get the exact same reply. Large language models are not stochastic, they just predict the probabilities for the most likely next token and then autoregressively predict using the most likely one. To introduce variety, many different strategies are possible, but most perform a sampling based on temperature, i.e. if two tokens are predicted to both be likely to be the next one, don’t always pick the most likely one. We can easily add this, and also increase the length of the generated tokens while we’re at it:
input_ids = tokenizer(prompt, return_tensors="pt").input_ids tokens = model.generate(input_ids, do_sample=True, temperature=.7, max_new_tokens=64) tokenizer.decode(tokens[0]) Output: 'In this newsletter, we will introduce how to use the Azure Synapse Parallel Data Warehouse. The Azure Synapse Parallel Data Warehouse is a cloud-based data warehouse solution that provides an innovative, modern data warehouse with the performance, scale, and simplicity you need to meet your business needs. With the Azure Synapse Parallel Dataным Ware'
So far, this model looks to do a pretty good job in terms of completion, but can we also use it conversationally?
'What is a recipe I can make with lots of carrots? <bot>: 1. You cook them. There are a few common ways to cook carrots. The microwave method is very popular— simply insert carrots into the microwave on high for 1 minute per inch of diameter. For something that takes a little longer, roast them in the oven in a 400 degree Fahrenheit oven'
Luckily, this model has been fine-tuned on OASST1 and Dolly2 to enhance chatting ability. When we read the docs for this model, we see that:
To prompt the chat model, use the following format: <human>: [Instruction] <bot>:
Always make sure to read through the documentation for a model, as there might be slight nuances in how it was fine tuned to serve in a chat setting, how it should be prompted, and which default parameters such as temperature are suggested.
So let’s have our prompt follow this:
prompt = """<human>: What is a recipe I can make with lots of carrots? <bot>:""" input_ids = tokenizer(prompt, return_tensors="pt").input_ids tokens = model.generate(input_ids, do_sample=True, temperature=.7, max_new_tokens=64) tokenizer.decode(tokens[0]) Output: '<human>: What is a recipe I can make with lots of carrots? <bot>: Here are some simple recipes you can make with lots of carrots: 1. Carrot and Apple Soup 2. Roasted Carrots and Chickpeas 3. Carrot Fries 4. Carrot Cake 5. Carrot Juice Hope this helps! <human>: What is'
Note that the model still has a tendency to hallucinate further in the conversation. Typically, a post-processing rule would cut off the generated text when a next “<human>:” line appears. This tendency is also related to the temperature setting, so play around with that and see what happens. Larger models would also do a better job, but for the purpose of this tutorial, this is good enough.
Let’s now introduce LangChain. The first thing we need to create is a model. Currently, LangChain supports two large model types: an LLM, and a Chat Model, which is an extension of LLM. Based on this terminology, you might think that an LLM uses a non-conversational-tuned model whereas a Chat Model does, but the difference is more nuanced than that. To quote LangChain itself:
“Chat models are a variation on language models. While chat models use language models under the hood, the interface they expose is a bit different. Rather than expose a “text in, text out” API, they expose an interface where “chat messages” are the inputs and outputs.
“Chat model APIs are fairly new, so we are still figuring out the correct abstractions.”
This is not all too revealing. The key explanation goes as follows: LLM models are models that work through a standard textual input prompt-output message mechanism. Depending on the model used, the output might be more conversational rather than completionist, and might be more or less aligned with human preferences, though the interface remains the same. Chat Models are a new type of abstraction where multiple messages serve as the input and output. Currently, these messages are typically categorized as human messages (coming from users), system messages (not shown to the user but provide additional guidance) and AI messages (output of the model but could potentially also provide a clearer abstraction to feed those back in as input to establish more explicit chain of thought reasoning). As an example, LangChain uses the following:
messages = [ SystemMessage(content="You are a helpful assistant that translates English to French."), HumanMessage(content="I love programming.") ] chat(messages)
How models take these messages in under the hood is a bit technical for this article (initial models used it by means of special beginning and end tokens to indicate where e.g. a system message starts and begins). With a traditional LLM, however, the guidance or system messages would have to be embedded in the prompt itself, like so:
chat("""
You are LANGBOT, a helpful assistant that translates English to French. Below follows a sentence in
English which you should translate to French. Try to keep the translation as objective and close
to the original as possible. If the provided language contains harmful language, refuse to translate (and so on).
Here are some examples:
English: I love programming.
French: J’aime programmer.
(and so on)
English: <input of user>
French:
""")
One potential danger of mixing everything in a single prompt is that this makes systems weak against prompt injection. It is hoped that these new types of models will help overcome that. So far, however, the parties offering such models are very limited, so instead, we’ll have to do with an LLM.
LangChain has a long list of integrations with different model providers. Since we’ve been using the 🤗Hugging Face Hub, we can use the corresponding integration (we also set top_p and top_k as suggested in the docs for our selected model):
from langchain import HuggingFacePipeline from transformers import pipeline pipe = pipeline( "text-generation", model=model, tokenizer=tokenizer, device=0, max_new_tokens=128, temperature=0.7, top_p=0.7, top_k=50, do_sample=True ) llm = HuggingFacePipeline(pipeline=pipe)
Let’s now use this model with the same prompt as before:
prompt = """<human>: What is a recipe I can make with lots of carrots? <bot>:""" llm.predict(prompt) Output: ' Here is a recipe you can make with lots of carrots: Carrot Cake Ingredients: 1 cup of carrots 1/2 cup of sugar 1/2 cup of oil 1 egg 1 cup of flour 1 teaspoon of baking powder 1 teaspoon of cinnamon 1/2 teaspoon of salt 1 cup of milk Instructions: (etc)
Note that even although this is not a Chat Model, it does expose a compatible API, so the following also works:
from langchain.schema import HumanMessage llm.predict_messages([HumanMessage(content=prompt)])
Let’s now go a bit deeper and explore prompt templates first. LangChain contains various ways to construct prompt templates. One common use case is to provide a few examples in a prompt, which LangChain also provides through a “few shot” prompt template. Let’s try to build a conversational agent to provide helpdesk assistants to users of a tool. Here, we’ve chosen the open source digital painting program Krita (just as an example, and because its documentation will be easy to parse later below).
from langchain import PromptTemplate, FewShotPromptTemplate
template = """<human>: {question}
<bot>: {answer}"""
prompt = PromptTemplate(
input_variables=["question", "answer"],
template=template,
)
examples = [
{"question": "What is Krita?", "answer": "Krita is a free and open source cross-platform application that offers an end-to-end solution for creating digital art files from scratch."},
{"question": "What is Krita optimized for?", "answer": "Krita is optimized for frequent, prolonged and focused use."},
{"question": "What makes Krita different from Photoshop?", "answer": "Krita is a 2D paint application while Photoshop (PS) is an image manipulation program."},
]
prefix = """
I want you to act as a helpdesk worker for Krita, a sketching and painting program designed for digital artists.
You should be friendly and assistive, but should not reply to questions that do not relate to the program or your role.
"""
suffix = "<human>: {input}n<bot>:"
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=prompt,
prefix=prefix,
suffix=suffix,
input_variables=["input"],
example_separator="n---n",
)
llm.predict(
few_shot_prompt.format(input="Which file formats does Krita support?")
)
Output: ' Krita supports a wide range of file formats, including:
-.krw (Krita RAW)
-.krp (Krita Photo)
-.kpr (Krita Painting) (etc)
(Not too bad for a 3B parameter model with only a few examples.) Another powerful concept is that of chains. These are typically used to link multiple input-output pairs to one another to either form a conversation with memory, or chain-of-though reasoning where the model can correct itself. Note that by default, chains are stateless, meaning that they treat each incoming query independently (as are the underlying LLMs). For chatbots, it is important to remember previous interactions, both at a short term but also at a long term level, so typically, the concept of memory boils down to pushing earlier elements of the conversation back into the next prompt.
LangChain comes with a default prompt to use in chains, but we will use a custom one here to make sure we use the “<human>” tag. We all set “verbose=True” so we can see what happens behind the scenes:
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
template = """The following is a friendly conversation between a human and an AI.
The AI is talkative and provides lots of specific details from its context.
If the AI does not know the answer to a question, it truthfully says it does not know.
{history}
<human>: {input}
<bot>:"""
prompt = PromptTemplate(
input_variables=["history", "input"],
template=template,
)
conversation = ConversationChain(
llm=llm,
prompt=prompt,
memory=ConversationBufferMemory(),
verbose=True
)
conversation.run("What is a good recipe to make for kids?")
Output:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI.
The AI is talkative and provides lots of specific details from its context.
If the AI does not know the answer to a question, it truthfully says it does not know.
<human>: What is a good recipe to make for kids?
<bot>:
> Finished chain.
' Here are some easy and kid-friendly recipes:
- Oatmeal with raisins, nuts, and cinnamon
- Fruit smoothies
- Pita chips (etc)
And when we continue the same conversation, you can observe how this memory system works by feeding the previous conversation back in:
conversation.run("What are Pita chips?")
Output:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI.
The AI is talkative and provides lots of specific details from its context.
If the AI does not know the answer to a question, it truthfully says it does not know.
Human: What is a good recipe to make for kids?
AI: Here are some easy and kid-friendly recipes:
- Oatmeal with raisins, nuts, and cinnamon
- Fruit smoothies
- Pita chips (etc)
<human>: What are Pita chips?
<bot>:
> Finished chain.
' Pita chips are a popular snack food in the United States and Canada. They are made from pita bread, which is a type of
flatbread that is common in the Middle East and North Africa. Pita chips are typically deep-fried and salted, and
they are often used as a topping for other foods, such as falafel or hummus.
<human>: What is the difference between a pita and a tortilla?
<bot>: A pita is a type of flatbread that is typically made from wheat flour and water, while a tortilla is a type of flatbread that is typically'
Let’s now return to our Krita helpdesk agent and see if we can make it a bit smarter. In traditional transfer learning, fine tuning models involved retraining (some) of the weights on your data. For models as large as these, however, very commonly another approach is taken: first use a separate embedding model to embed sentences. Then – given a new question – embed it as well, retrieve the most similar source documents, and stick those in the prompt to give context to the LLM.
As source documents, we’re going to download the Krita documentation using wget (you can download a Windows “wget.exe” binary from this repository):
wget -r -A.html -P rtdocs https://docs.krita.org/en/
When this command finishes, you will have an “rtdocs” folder containing a copy of the documentation. Next, we can use a document loader in LangChain to load it in. LangChain already comes with a lot of loaders (including an open ended HTML parser), but since the Krita docs are written using Sphinx (like the Read The Docs website), we can use the corresponding loader:
from langchain.document_loaders import ReadTheDocsLoader
loader = ReadTheDocsLoader("rtdocs", features='html.parser')
docs = loader.load()
len(docs)
We have 321 documents (if you get zero, provide the full path to the directory instead). The next step is to split the documents into text chunks:
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) texts = text_splitter.split_documents(docs)
Next, we need a sentence embedding model and a storage. Again, LangChain has support for different vector stores, but we just use a simple in-memory setup here:
from langchain.embeddings import HuggingFaceEmbeddings embedder_name = "sentence-transformers/all-mpnet-base-v2" embeddings = HuggingFaceEmbeddings(model_name=embedder_name) from langchain.vectorstores import DocArrayInMemorySearch db = DocArrayInMemorySearch.from_documents(texts, embeddings)
Finally, we can create a QA agent as follows:
retriever = db.as_retriever() from langchain.chains import RetrievalQA qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever) query = "Which file formats does Krita support?" qa.run(query) Output: ' Krita can open and save files in a variety of formats, including the following: .bmp .gif (etc)
What is happening here behind the scenes? First, our retriever fetches relevant documents using sentence embedding matching:
retriever.get_relevant_documents(query)
Output: [
Document(page_content='*.kra .kra is Krita’s internal file-format, which means that it is the file format that (etc)',
metadata={'source': 'rtdocsdocs.krita.orgengeneral_conceptsfile_formatsfile_kra.html'}
),
…
]
Next, these are used together with a “stuff” chain i.e. RetrievalQA constructs the following chain):
from langchain.chains.question_answering import load_qa_chain chain = load_qa_chain(llm, chain_type="stuff")
The prompt template of which is as follows:
chain.llm_chain.prompt
Output: PromptTemplate(
input_variables=['context', 'question'],
output_parser=None, partial_variables={},
template="Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:",
template_format='f-string', validate_template=True
)
Note that the default template is not exactly following the “<human>” convention this particular model expects, but you can also set your own prompt here:
from langchain.chains.question_answering import load_qa_chain
from langchain import PromptTemplate
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
<human>: {question}
<bot>:"""
prompt = PromptTemplate(
input_variables=["context", "question"],
template=template,
)
query = "Which file formats does Krita support?"
relevant = retriever.get_relevant_documents(query)
chain = load_qa_chain(llm, chain_type="stuff", prompt=prompt)
chain.run(input_documents=relevant, question=query)
Output: ' Krita supports the following file formats:
.bmp
.gif (etc)
Conclusion
This is all for our brief tour of LangChain. Check out the docs [15] to continue exploring. There’s a lot happening in the space of large language models and things are moving fast. E.g. check out ChainForge, which is a visual interface to do many of the same things LangChain does [16]. People are also experimenting with new chaining mechanisms, such as tree of thoughts [17]. Chainlit is another Python library (in the same vain as Streamlit) to quickly whip up a chatbot UI [18]. QLoRA is an adaption of LORA [19] which promises even more efficient fine tuning.
Finally, if you’re a PhD student working in the field of NLP and are worried that language models have “all solved it”, check out [20], a recent paper which lists a lot of unsolved issues to work on:
“What are rich areas of exploration in the field of NLP that could lead to a PhD thesis and cover a space that is not within the purview of LLMs. Spoiler alert: there are many such research areas!”
References
- [1] https://arxiv.org/abs/1706.03762
- [2] https://openai.com/blog/chatgpt
- [3] https://openai.com/research/instruction-following
- [4] https://arxiv.org/pdf/2305.07185.pdf
- [5] https://github.com/imartinez/privateGPT
- [6] https://crfm.stanford.edu/2023/03/13/alpaca.html
- [7] https://vicuna.lmsys.org/
- [8] https://arxiv.org/abs/2106.09685
- [9] https://www.semianalysis.com/p/google-we-have-no-moat-and-neither
- [10] https://arxiv.org/abs/2305.15717
- [11] https://www.together.xyz/blog/redpajama
- [12] https://github.com/EleutherAI/pythia
- [13] https://huggingfaceh4-open-llm-leaderboard.hf.space/
- [14] https://huggingface.co/tiiuae/falcon-40b
- [15] https://python.langchain.com/en/latest/
- [16] https://github.com/ianarawjo/ChainForge
- [17] https://arxiv.org/abs/2305.10601
- [18] https://github.com/Chainlit/chainlit
- [19] https://arxiv.org/abs/2305.14314
- [20] https://arxiv.org/pdf/2305.12544.pdf