
Contributed by: María Óskarsdóttir, Bart Baesens
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
Predictive analytics is a rich field in the world of data mining. It has a wide range of applications, such as for customer relationship management, marketing and risk modelling. Networks are being exploited more frequently for predictive modelling, commonly in form of social network analysis. The observations in a network, the nodes, do not behave the in same way as observations in regular datasets, because they are all connected and may therefore have an effect on each other.
At least two common ways exist to make predictions using information from networks. Firstly, the information about the connected nodes and links can be used to make inferences in the network directly, for example regarding age and gender of people. This is known as network learning. Secondly, featurization can be used to extract features from the network and subsequently build predictive models with a binary classifier such as logistic regression.
The art of featurization is complex and not always a straight forward task. Transforming a network into attributes which are descriptive and represent the network correctly is difficult and depends on the application. It has been widely studied, with many proposed methods and here we’ll discuss a state-of-the art method called node2vec [1]. node2vec is composed of two methods that work together to create a set of representative features for a given network. First, a two-step random walk travels through the network to create paths of nodes which subsequently are fed into a skip gram model to generate the features. We will discuss these two parts separately, starting with the latter one.
The Skip Gram Neural Network Architecture [2, 3] was developed for natural language processing, to learn which words have a similar context. This model trains a neural network for each word in a set of words, based on the words that appear around it in some text. The output of the model is a vector with the probability of each word appearing next to the input word. The skip gram model does however not use the output of the model, but the hidden layer of the neural network, and this hidden layer is in fact the generated feature set. To do this, the neural network is trained on a weight matrix where each row corresponds to one word and each column represents each of the features to be generated. When applied to networks, there are of course no words, but instead there are nodes that are connected and build paths, and appear together in that sense. However, there are various ways to generate paths in a network, and the results can be very different.
The paper [1] proposes a customizable two step random walk procedure to sample paths within a network. Two parameters, the return parameter, p, and the in-out parameter, q, allow the user to specify how the graph should be traversed when creating paths. The first parameter p determines the likelihood of immediately going back to an already visited node, with a low value meaning it is more likely to go back whereas a higher value will drive the walk to visit nodes further way. The second parameter, q, determines whether the walk stays close to one node, exploring the same neighborhood, analogous to a breath first search, or whether it travels further away thus exploring more nodes, similar to a depth first search. Multiple paths are created this way before they are fed into the skip gram model for feature generation.
node2vec is a scalable method, which as has been show to outperform other methods when applied to multi-label classification.
Application
We will demonstrate how node2vec can be used for predictive modelling. Given a call network of customers of a telecommunication company, our goal is to predict three of their characteristics, namely churning in the future, age and gender. We assume that these characteristics are known for a fraction of the customers and aim to predict them for the rest using the features created by node2vec. In addition, both the churn and gender variables consist of two labels each whereas age is categorized into 4 groups, making it’s prediction a multi label classification problem.
Before starting the analysis, values for the parameters p and q of the two step random walk must be determined. As in [1] we do this with a grid search over p,q ∈ {0.25,0.5,1,2,4} and afterwards build a predictive model on 10% of the resulting dataset. The values of p,q which give the best performing model for each characteristic variable are then chosen. These values can be seen in the table below:

Optimal values for the return and in-out parameters for the three predictive variables.
Based on the table we can see that the type of paths sampled for each characteristic are quite different, meaning that they require variable information from the network. In the case of churn, q is large which means that the random walk is biased towards nodes that are very close to the starting node. The fact that p is small ensures that the walk is more likely to backtrack when exploring the graph, meaning that it tends to stay close to the same neighborhood. For the prediction of age, q is again large and so is p, but since the latter is smaller than max(1,q), it implies that the walk will stay close to the starting node, but will still travel further away than in the case of churn. Finally, looking at the parameter values for gender, q is very low, which means that the walk will be inclined to travel further away from the starting node. But since p is so small, the walk will also want to backtrack a step. Overall this could mean that the paths consist of small samples of the ego-net of multiple nodes.
Given the optimal values of the walk parameters for each predictor, we start a more extensive model building process. We want to explore the performance of predictive models given a variation in portion of known and unknown labels in the graph. Concretely, we split our dataset – composed of the features generated by node2vec– into train and test sets ranging from 10% to 90%, assuming that the labels of the test set are unknown and then train models on the train sets in order to predict them.
We start by discussing the results of the churn prediction exercise. The performance of the resulting models can be seen in the following figure, which displays the their AUC values as a function of fraction of labelled data. As can be seen, model performance increases substantially as more of the training data is labelled, which is consistent with literature. Interestingly, reasonably good performance can be achieved with only 30%−40% of know labels.
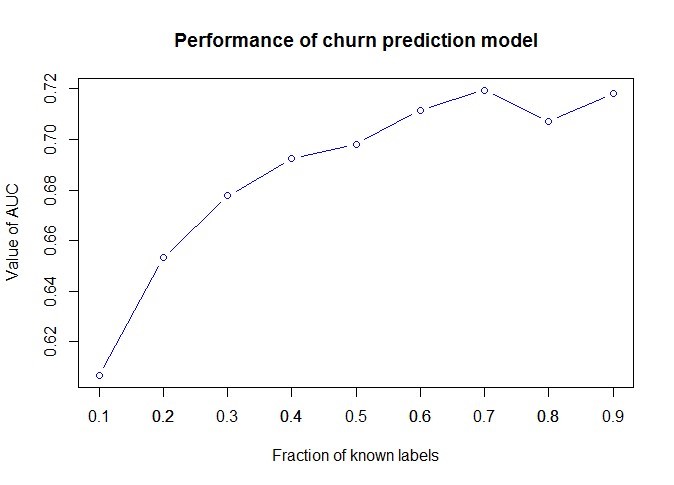
AUC of prediction model
The figures below show the performance of gender and age prediction models in terms of Macro-F1 and Micro-F1 scores, respectively. These scores are commonly used to represent precision of multi-label classification models. In these two cases we also see an increase in performance as more labels are known, except in the case of Macro-F1 values for the age model, which decrease a little after 70%. This can be explained by the fact that one of the classes is much smaller than the others and therefore underrepresented, and could probably be solved with sampling of the data prior to model building.
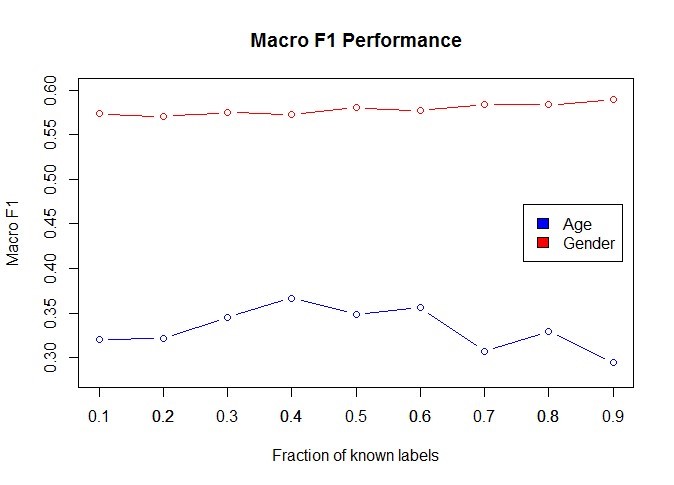
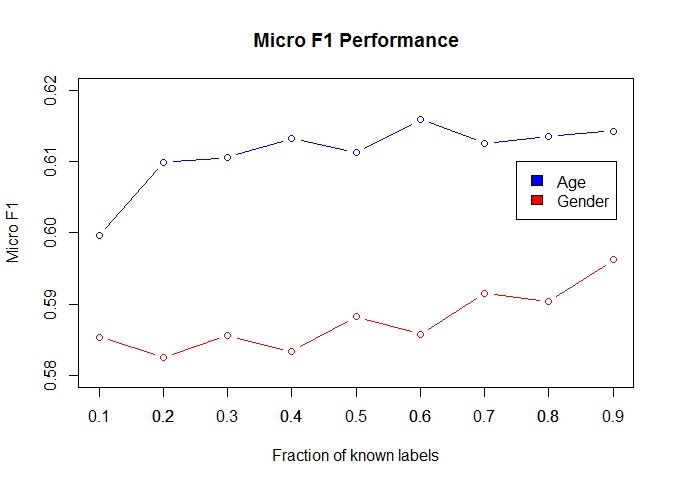
Conclusion
Node2vec is a novel and very interesting method for featurization of networked data. It applies a commonly used method, the step-gram architecture, to paths sampled from graphs, to generate a high dimensional set of features for the nodes in the network. Subsequently it is easy to use these features to build well performing predictive models, even when only a small part of the labels is known. We have demonstrated this by trying node2vec out on a call network to predict both demographic features and which customers are most likely to churn.
Another useful application of node2vec is the ability to characterize the connectivity of the network in terms of the two-step random walk parameters, p and q. They can give an inclination of whether homophily is present in the network or whether structural equivalence is high, as is discussed in [1]. It is a useful insight in many applications of networks and social network analysis.
References
- Grover, Aditya Grover and Leskovec, Jure node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016.
- Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781, 2013.
- Mikolov, T., and J. Dean. “Distributed representations of words and phrases and their compositionality.” Advances in neural information processing systems, 2013.