
Contributed by: Michael Reusens, Bart Baesens, Wilfried Lemahieu
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
In this short article we will discuss a major flaw in classical evaluation strategies for recommender systems, as well as ways to solve it. Let’s start by explaining what we understand with a recommender system. A commonly used definition is the following: “Recommender Systems are software tools and techniques providing suggestions for items to be of use to a user.”. Some famous examples of recommender systems can be found on Amazon (recommending products to buy), Netflix (recommending video-content to watch) and LinkedIn (recommending vacancies to job seekers).
The image below shows a schematic overview of how most recommender systems work. They take as input a user to generate recommendations for, all potential recommendable items and historic data that gives insight which users are interested in which items (such as likes, star-ratings, clicks, …). Based on these inputs they make a prediction on how interesting each item is for the user. Finally, the items are sorted from most to least interesting, and the N (N can be chosen based on the application) top items are recommended to the user.
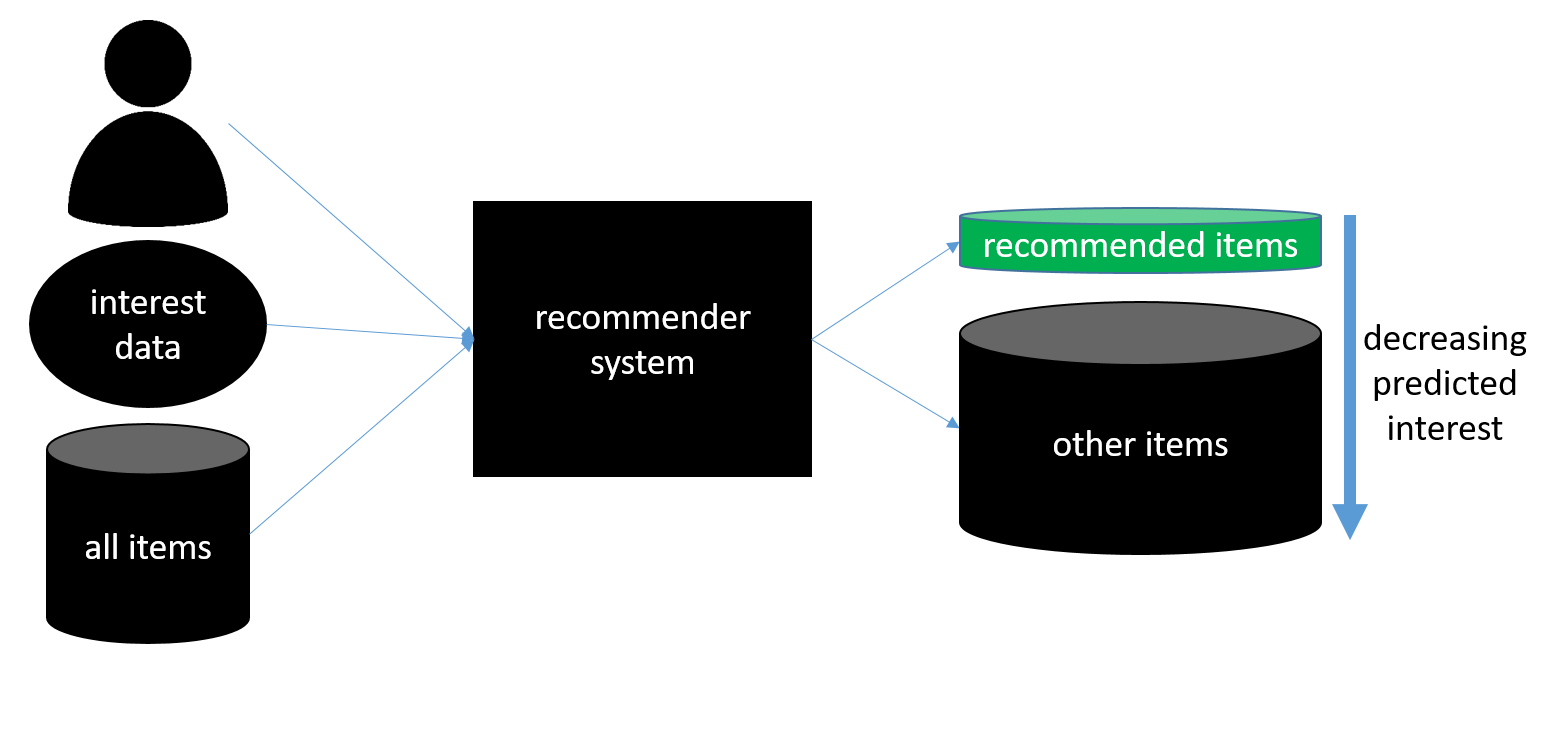
Given this set-up, recommender systems are often perceived as a type of classifiers who’s task it is to predict if there is interest between a given user-item pair. Because of this, many evaluation strategies applicable to “standard” classification tasks have also become popular in recommender system evaluation.
An example evaluation could go as follows. A first step is gathering a dataset containing historic information on which users are interested (or disinterested) in which items. From a classification perspective this is our labeled dataset in which user-item is FALSE if there is no interest (or disinterest) of the user in the item and TRUE if there is an observed interest. Once we have such dataset, we split it in 2 (or use cross-validation): a training set containing the first interests of each user, and a test set containing the x last observed interests of each user. After this split, we generate recommendations based on the data in the training set and measure to what degree the items recommended by the system match the interests in the test set (these are the items in which we know the user is interested). Common metrics here are accuracy, recall, precision, … This methodology is represented in the image below.

However, if we think more thoroughly about this type of evaluation, we are actually rewarding algorithms that recommend items a user would have looked at on their own (otherwise interest for this item would not be visible in the test set) raising the question of what the recommender’s benefit is in the first place (besides faster information retrieval). Even worse, this type of evaluation potentially punishes recommender systems that recommend items that are extremely relevant for a user, but they just did not know of their existence. This type of recommendations are called serendipitous recommendations, and they are extremely valuable. The image below is a visual representation of what is going on.
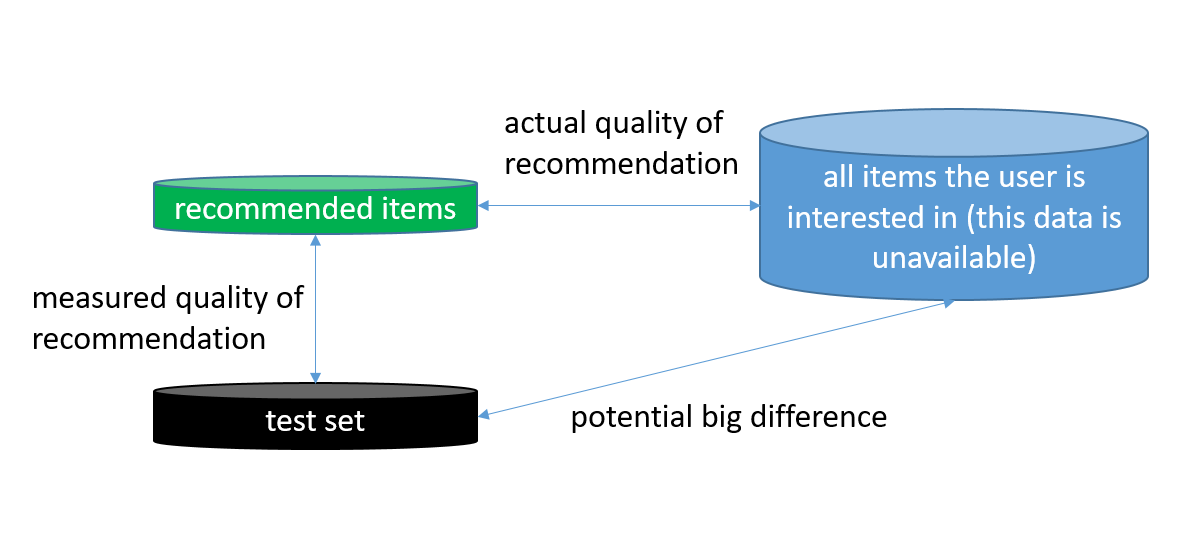
So, how can you solve this? On the one hand you want to make sure that the recommender system will recommend items a user is actually interested in (measured by the evaluation strategy above), but on the other hand you want the recommendations to consist of items that are not super obvious, and a user would not have thought of him/herself (penalized by the evaluation strategy above).
The solution: use online evaluation! By presenting your recommendations to actual users you do not rely on historic test sets, which is limited for the reasons mentioned above. Common metrics for online recommendation quality are click-through rate, time spent looking at recommended items, … Of course, online user testing also has its flaws: it is expensive and you potentially expose your users (which are your clients, customers, patients, …) to potentially bad recommendations, causing harm to your reputation.
A commonly used trade-off is the following: use offline evaluation to weed out the worst performing recommender systems and narrow down the pool of potential recommender systems. The quality of the remaining systems can then be tested on real users, using for example A/B-testing set-ups.
Further reading: Shapira, B., Ricci, F., Kantor, P. B., & Rokach, L. (2011). Recommender Systems Handbook