
Contributed by: Bart Baesens, Seppe vanden Broucke
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
Deploying a machine learning model is by no means a trivial exercise. In real-world machine learning systems, only a small fraction is comprised of actual machine learning code. There is a vast array of surrounding IT infrastructure and processes to support their deployment, application and evolution. Many key challenges accumulate in such systems, some of which are related to data dependencies, model complexity, reproducibility, testing, monitoring, and dealing with changes in the external world. These challenges are also often described as technical debt.
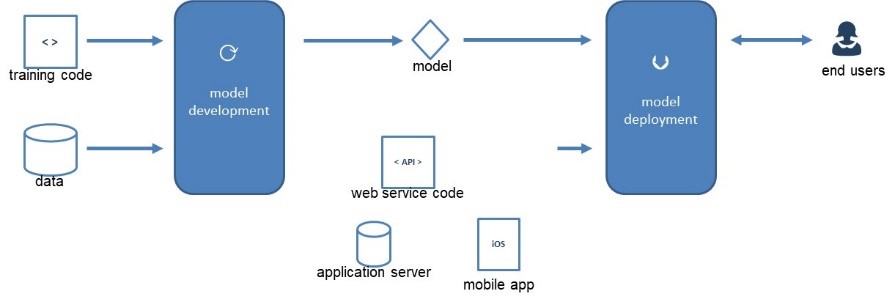
In the above figure, you can see an example of a typical machine learning deployment process model. We start from training code and data to the left. Based on this, the machine learning model can be developed. The model can then be deployed to the end users using web service code, an application server or as a mobile app. Although it looks like a simple straight-through process, various challenges undoubtedly arise along the way.
A first important aspect relates to the lineage of data dependencies. The machine learning model will make use of various data sources. The availability of good metadata management is essential to the successful deployment of a machine learning model. We should ensure that all data and its preprocessing is available to the machine learning model at prediction time.
The machine learning model itself can be deployed as an API, embedded in a web app or a mobile app. It can be scheduled to run every hour, day, week or month. Note the difference between the machine learning development environment (Jupyter, Anaconda, R…) and the IT environment used for deployment such as Java, .NET, etc. It is hereby important to keep the model changes in sync with application changes.
Development governance is essential for successful machine learning model deployment. The training code should be well-documented. Good collaboration and versioning facilities are essential. An important question is whether the training code can be easily reproduced so as to re-train the model periodically. Also be aware of the runs on my machine phenomenon, and try out the machine learning model on various IT platforms.
Model governance is another important aspect. How is the model actually deployed? Using a common platform, using containerization or virtualization or both? Is versioning support provided for models? Remember, older models might still be successfully used for benchmarking purposes. Can models serve as data, or can the output of one model be easily used in other models/projects? Is lineage kept in this case? Is there metadata available (e.g. when was the model last updated? by who?).
Model monitoring or backtesting is also important. This relates to inputs, outputs and usage. Do we know when input data is changing, or when outputs such as probabilities change? Are errors properly reported and followed up?
Many of these deployment issues we just raised are also well known in traditional software engineering. Think of testing, monitoring, logging, and structured development processes, but also Continuous development, integration, deployment (CI/CD). However, in the context of ML productionization, many of these are hard to apply since ML models degrade silently. Moreover, data definitions change, people take actions based on model outputs, other externalities change (different promotions, products, focus…). Models will happily continue to provide predictions, but as concept drift increases, their accuracy and generalization power will decrease over time. Hence, a rock solid model governance infrastructure is key!
Some common examples of deployment platforms that aim to offer solutions for the problems mentioned above are Algorithmia, Octopus Deploy, mlflow, H2O.ai, Data Kitchen, Cortex and Domino. Some firms have tailored in-house environments such as Uber’s Michelangelo, Facebook’s FBLearner flow, Spotify’s Airflow, Netflix’ ML Platform, and Airbnb’s Bighead.
Below are some best practices that we’ve found to work well.
During model-development, data sources are typically dispersed and entangled. Hence, it is hard to keep track of the data used during a model’s construction. A common source of data should be set up and used both during model development and in production. Common data preprocessing steps should be incorporated in the data layer, made available as e.g. a separate table, Hive source, HDFS location, …, instead of being duplicated over different model pipelines. It is important to not split up the data layer in “raw”, “processed” and “final” stages. Data is always raw and never final. It is recommended to focus instead on integrating the different sources in a common platform. When using an ad-hoc data source, try to investigate as early as possible in the development process whether this data source can be ingested in the common layer. It is important to consider for every data input whether the data will be available at prediction in a timely manner. Don’t forget to set up a structured data dictionary containing data definitions and metadata information. This includes data purpose constraint definitions (e.g. GDPR and other regulatory constraints). Also prevent data elements to be used if not possible. Both data and metadata come with versioning so it is important to keep historical records available, in other words, you should be able to retrieve the state of the data as when it was during training. Note that this applies to streaming data as well. Finally, make sure that the predictions of machine learning models are ingested in the data layer, if they are to be used as an input for other models.
Another issue is the aspect of models models failing silently, i.e. their accuracy decreases over time. Changing data definitions might still lead to models using those data elements suddenly failing. It is important to keep track of the inputs provided to the machine learning model. Do new missing values occur, do the distributions of variables change, or do new categorical levels appear? Also keep track of the model outputs as well over time. Does the probability distribution of the model change over time? Does usage decrease? Do predictions fail? How long does it take to call the model?
Another issue is where do models run? How will they be exposed in the organization? Two common patterns are push and pull. According to the push pattern, the model is scheduled to run regularly over a batch of data (or a real-time stream of data), with outputs being saved to the data layer, e.g. to Hadoop, an FTP server, a relational database table, or an Excel file. According to the pull pattern, the model is deployed as an API or microservice to be queried by outside consumers. In both cases, an isolated runtime environment needs to be provided!
Finally, it is important to be aware of the trade-off between flexibility and robustness and allow for experimentation for ad-hoc, new or experimental projects. To do this, recall to start with the data and make the data sources available in a central managed location. Once a machine learning project matures, you can move towards the reproducible and governed environment. Important hereby is to consider the preferred working environment of machine learners. Hence, many deployment platforms integrate with standard packages such as scikit-learn, Tensorflow and allow developing using Jupyter Notebooks. An example of this is Netflix who pushes Notebooks directly to production using Papermill. Finally, not all machine learning models end as an API. In many cases, the purpose is to provide a report, dashboard, or show insights. Hence, also consider the link with the business intelligence (BI) environment.