
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
Contributed by: Bart Baesens and Seppe vanden Broucke. This article was adopted from our Customer Lifetime Value Modeling book. Check out clvbook.com to learn more.
Various deployment strategies can be used to replace an old decision model, which could be either expert based or analytical, by a new, more sophisticated, machine learning model. A first strategy is a direct changeover where the old system is instantaneously replaced by the new machine learning model. Obviously, this is a risky strategy because of the potential shock effect that it may cause. A more conservative strategy is a parallel changeover where two models are run at the same time. In case the new model fails, there is always the fallback option to the old model. An example could be a weighted combination of recommendation scores during a transition period of, e.g., six months, where initially a higher weight is attached to the old score, but as the transition period progresses, this weight decreases and a higher weight is assigned to the new recommendation score. This is a costly strategy as one needs to run and maintain two models. A phased changeover strategy introduces the new analytical output step by step in the business applications.
In real-world machine learning (ML) systems, only a small fraction is comprised of actual ML code. There is a vast array of surrounding IT infrastructure and processes to support their deployment, application and monitoring. Many key challenges accumulate in such systems, some of which are related to data dependencies, model complexity, reproducibility, testing, monitoring, and dealing with changes in the external world. These challenges are also often described as technical debt.
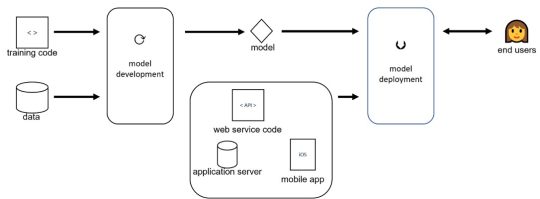
In the above Figure you can see an example of a typical machine learning deployment process model. It starts from training code and data to the left. Based on this, the machine learning model can be developed. The model can then be deployed to the end users using web service code, an application server or as a mobile app. Although it looks like a simple straight-through process, various challenges arise along the way as we discuss in what follows.
A first important aspect relates to the lineage of data dependencies. The machine learning model will make use of various data sources. The availability of good metadata management is essential to the successful deployment of a machine learning model. We should ensure that all data and its preprocessing is available to the machine learning model at prediction time. Imagine for example that we created dummy variables from a categorical variable that provides product possession information, in order to predict customer churn. If one day there is a new product, we should make sure that our data preprocessing pipelines are able to handle this and assess the impact on the model. Therefore, smart data scientists and data engineers build in checks in code for the data preprocessing that warn if there are (unexpected) changes to the input data. Many firms nowadays invest in data governance, which refers to the process of managing aspects such as the availability and security of data according to internal data policies and standards. Data governance aims to ensure the consistency and trustworthiness of data.
The analytical model itself can be deployed as an API, embedded in a web app or a mobile app. It can be scheduled to run every hour, day, week or month. Note the difference between the machine learning development environment (Jupyter, Anaconda, R, …) and the IT environment used for deployment such as Java, .NET, etc. It is important to keep the model changes in sync with application changes.
Development governance is essential for successful machine learning model deployment. The training code should be well-documented. Good collaboration and versioning facilities are essential. An important question is whether the training code can be easily reproduced so as to re-train the model periodically. Also be aware of the ‘runs on my machine’ phenomenon, and try out the machine learning model on various IT platforms. To facilitate the development and later deployment of your models, firms nowadays rely on containerized solutions such as Docker.
Many of these deployment issues we just raised are also well known in traditional software engineering. Think of testing, monitoring, logging, and structured development processes, but also Continuous development, integration, deployment (CI/CD). However, in the context of ML productionization many of these are hard to apply since ML models degrade silently. Moreover, data definitions change, people take actions based on model outputs, other externalities change (different promotions, products, focus…). Models will happily continue to provide predictions, but as concept drift increases, their accuracy and generalization power will decrease over time. Hence, a rock solid model governance infrastructure is key to successful machine learning model deployment.