
By: Seppe vanden Broucke, Bart Baesens
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
The concept of Business Process Management (BPM) has become commonplace in many enterprises and institutions. Broadly put, BPM aims to provide an encompassing managerial approach in order to align an organization’s business processes with the concerns of every involved stakeholder. A business process then is a collection of structured, inter-related activities or tasks, which are to be executed to reach a particular goal (produce a product or deliver a service). Involved parties in business processes include, among others, managers (denoted as the “process owners”), who expect work to be delegated swiftly and in an optimal manner; employees, who desire clear and understandable guidelines and tasks that are in line with their skillset, and clients, who — naturally — expect efficiency and quality results from their suppliers. The figure below shows an example business process model for a simple insurance claim intake process:
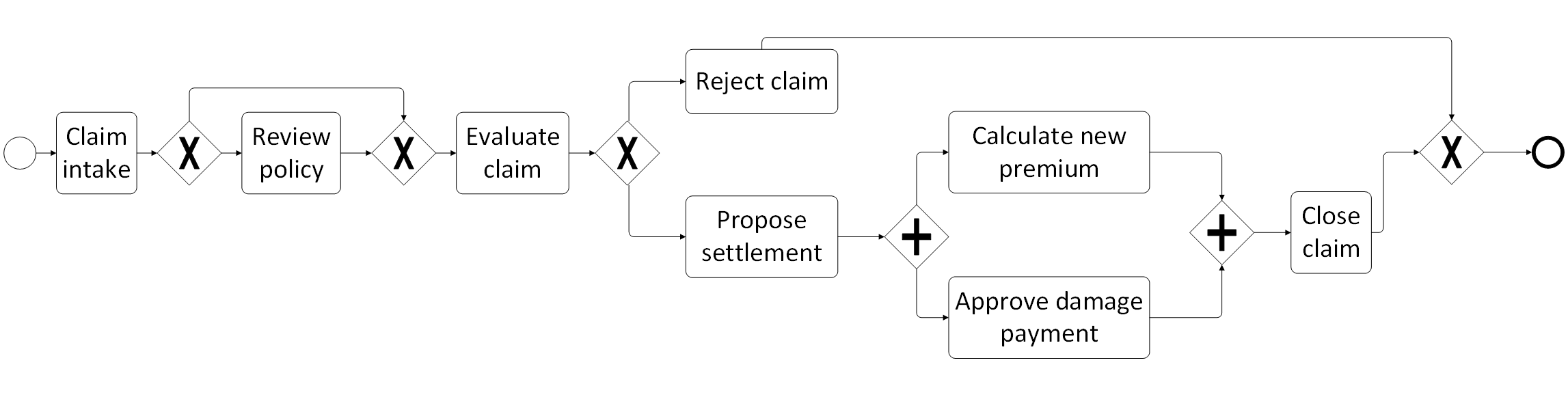
BPM is oftentimes described as a “process optimization”-methodology and hence mentioned together with related quality control terms such as Total Quality Management (TQM), Six Sigma, or Continuous Process Improvement methodologies. However, this description is somewhat lacking. True, one significant focal point of BPM is the actual improvement and optimization of processes, but the concept also encompasses best practices towards the design and modeling of business processes, monitoring (consider for instance compliance requirements), and gaining insights by unleashing analytical tools on recorded business activities. All these activities are grouped within the “Business Process Management Lifecycle”, which starts with the design and analysis of a business process (modeling and validation), its configuration (implementation and testing), its enactment (execution and monitoring) and finally, the evaluation, which in turn leads again to the design of new processes.
In this article, we will guide you through an overview of state of the art Business Process Analytics techniques. We set out by zooming in on the “evaluation” step of the BPM lifecycle, as it is mainly in this phase where concepts such as Business Process Analytics and Process Intelligence have made their mark during the past years. As the methodology of BPM has matured, many vendors have begun offering process-aware querying, reporting and OLAP support tools. However, we also highlight novel, predictive analytics-inspired techniques, bringing Business Process Analytics closer to the fields of Data Mining and Machine Learning — hence allowing practitioners to go further than user-driven reports. Furthermore, these state of the art techniques also help to “close the loop” of the BPM lifecycle, where the deep analysis performed on business processes also supports the design, modeling, monitoring, and execution of a company’s activities.
Process Intelligence
The concepts of Business Process Analytics and Process Intelligence originally positioned themselves within the “evaluation”-phase of the BPM lifecycle, thus dealing mostly with post-design, post-execution based reporting and analysis tasks. Just as with Business Intelligence (BI) in general, however, Process Intelligence has evolved into a very broad term encompassing a multitude of tools and techniques, and hence nowadays can include basically anything that provides information to support decision-making.
As such, in similar fashion as occurred with traditional (“flat”, or tabular) data oriented tools, many vendors and consultants have defined Process Intelligence to be synonymous with process-aware query and reporting tools, oftentimes combined with straightforward visualizations in order to present aggregated overviews on business actions. In many cases, a particular system will present itself as being a helpful tool towards process evaluation by providing key performance indicator (KPI) dashboards and scorecards, thus presenting a “health report” for a particular business process. In some cases, such tools are presented as monitoring and improvement tools as well (as such covering another phase in the BPM lifecycle), especially when they come equipped with real-time capabilities, compared to batch reporting where the gathering and preparation of reports follows — in some cases long — after the actual process execution. Many process-aware information support systems also provide Online Analytical Processing (OLAP) tools to view multidimensional data from different angles and to drill down into detailed information. Another term which has become commonplace in a Process Intelligence context is Business Activity Monitoring (BAM), which refers to real-time monitoring of business processes, thus related to the real-time dashboards mentioned above, but oftentimes also reacting immediately if a process displays a particular pattern. Corporate Performance Management (CPM) is also another buzzword for measuring the performance of a process or the organization as a whole.
Although all the tools described above, together with all the three-letter acronym jargon, are a fine way to measure and query many aspects of a business’ activities, most tools unfortunately suffer from the problem that they are unable to provide real insights or uncover meaningful, newly emerging patterns. Just as for non-process related data sets, although reporting, querying, inspecting dashboard indicators, aggregating, slicing, dicing and drilling are all perfectly valid and reasonable tools for operational day-to-day management, they all have little to do with real Process Analytics — the emphasis being placed on “analytics”. The main issue lies in the fact that such tools inherently assume that users and analysts already know what to look for, as writing queries to derive indicators assumes that one already knows these indicators of interest. As such, patterns that can only be detected by applying real analytical approaches remain hidden. Moreover, whenever a report or indicator does signal a problem, users often face the issue of then having to go on a scavenger hunt in order to pinpoint the real root cause behind the problem, working all the way down starting from a high-level aggregation towards the source data.
Due to the downsides of traditional reporting tools, a strong need is emerging to go further than straightforward reporting in today’s business processes and to start a thorough analysis directly from the avalanche of data that is being logged, recorded, stored and readily available in modern information support systems. This leads us to the discipline of Process Mining, which aims to provide analysts with true Business Process Analytics techniques.
“Process Mining”: Real Business Process Analytics
In the past decade, a new research field has emerged, denoted as “Process Mining”, which positions itself between BPM and traditional Data Mining. The discipline aims to offer a comprehensive set of tools to provide process-centered insights and to drive process improvement efforts. Contrary to Business Intelligence approaches, the field strongly emphasizes a bottom-up approach, starting from real-life data to drive analytical tasks. Process Mining builds upon existing approaches, such as Data Mining, Business Intelligence and model-driven design methodologies, but is more than just the sum of these components. Traditional Data Mining techniques are too data-centric to provide a solid understanding of the end-to-end processes in an organization, whereas Business Intelligence tools on the other hand focus on simple dashboards and reporting; it is exactly this gap that is narrowed by Process Mining tools.
The most commonly known task within the area of Process Mining is called Process Discovery (or also: Process Identification), where analysts aim to derive an as-is process model, starting from the data as it is recorded in process-aware information support systems, instead of starting from a to-be descriptive model and trying to align the actual data to this model. A significant advantage of Process Discovery is the fact that only a limited amount of initial data is required to perform a first — exploratory analysis.
Consider for example the insurance claim handling process as it was depicted in the figure above. To perform a Process Discovery task, we start our analysis from a so called “event log”: a recorded data table listing the activities that have been executed during a certain time period, together with the case (the process instance) they belong to. A fragment of such an event log can look as follows:
| “Insurance claim handling” event log | |||
| Case Identifier | Start Time | Completion Time | Activity |
| Z1001 | 2013-08-13 09:43:33 | 2013-08-13 10:11:21 | Claim intake |
| Z1004 | 2013-08-13 11:55:12 | 2013-08-13 15:43:41 | Claim intake |
| Z1001 | 2013-08-13 14:31:05 | 2013-08-16 10:55:13 | Evaluate claim |
| Z1004 | 2013-08-13 16:11:14 | 2013-08-16 10:51:24 | Review policy |
| Z1001 | 2013-08-17 11:08:51 | 2013-08-17 17:11:53 | Propose settlement |
| Z1001 | 2013-08-18 14:23:31 | 2013-08-21 09:13:41 | Calculate new premium |
| Z1004 | 2013-08-19 09:05:01 | 2013-08-21 14:42:11 | Propose settlement |
| Z1001 | 2013-08-19 12:13:25 | 2013-08-22 11:18:26 | Approve damage payment |
| Z1004 | 2013-08-21 11:15:43 | 2013-08-25 13:30:08 | Approve damage payment |
| Z1001 | 2013-08-24 10:06:08 | 2013-08-24 12:12:18 | Close claim |
| Z1004 | 2013-08-24 12:15:12 | 2013-08-25 10:36:42 | Calculate new premium |
| Z1011 | 2013-08-25 17:12:02 | 2013-08-26 14:43:32 | Claim intake |
| Z1004 | 2013-08-28 12:43:41 | 2013-08-28 13:13:11 | Close claim |
| Z1011 | 2013-08-26 15:11:05 | 2013-08-26 15:26:55 | Reject claim |
Based on real-life data as it was stored in event log repositories, it is possible to derive an as-is process model, providing an overview on how the process was actually executed in real life, instead of starting — and having to start with — a prescriptive to-be process model. To do so, a variety of Process Discovery algorithms can be applied, from which process maps are obtained such as the one shown in the figure below:
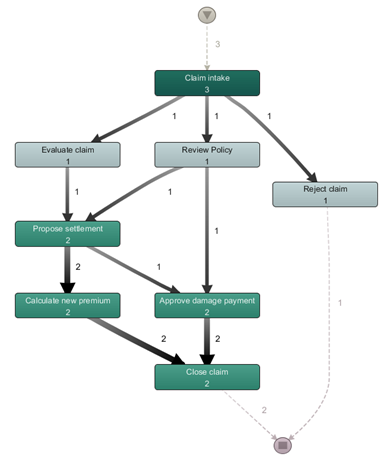
Note that these process maps can be annotated by various information, such as frequency counts of an activity’s execution (as in the figure above), or with performance based information (mean execution time, for instance). Note that — together with solid filtering capabilities — visualizations such as these provide an excellent means to perform an exploratory analysis to determine bottlenecks, process deviations and exceptions, compared when having to work with “flat data”-based tools (e.g. analyzing the original event log table using spreadsheet software).
Process Discovery is not the only task that is covered by Process Mining. One other particular analytical task is denoted as Conformance Checking and aims to compare an event log as it was executed in real life with a given process model (which could be either discovered or given). This then allows for quickly identifying and localizing deviations and compliance problems.
Consider once more our example event log. When comparing this event log on a process model (prescriptive or discovered), we can observe some deviations. The following depicts the result after “replaying” process instance “Z1004”. As can be seen, a compliance violation occurred during the execution of the “Propose settlement” activity, due to a non-executed but expected “Evaluate claim”-activity, which needs to precede the proposal of a settlement. After the compliance violation, the following tasks are able to execute in a normal fashion but are marked as “dubious”. As can be gathered from this example, Conformance Checking related techniques provide a powerful and immediate means to uncover root causes behind deviations and compliance violations in business processes and respond to such deviations in a timely fashion.
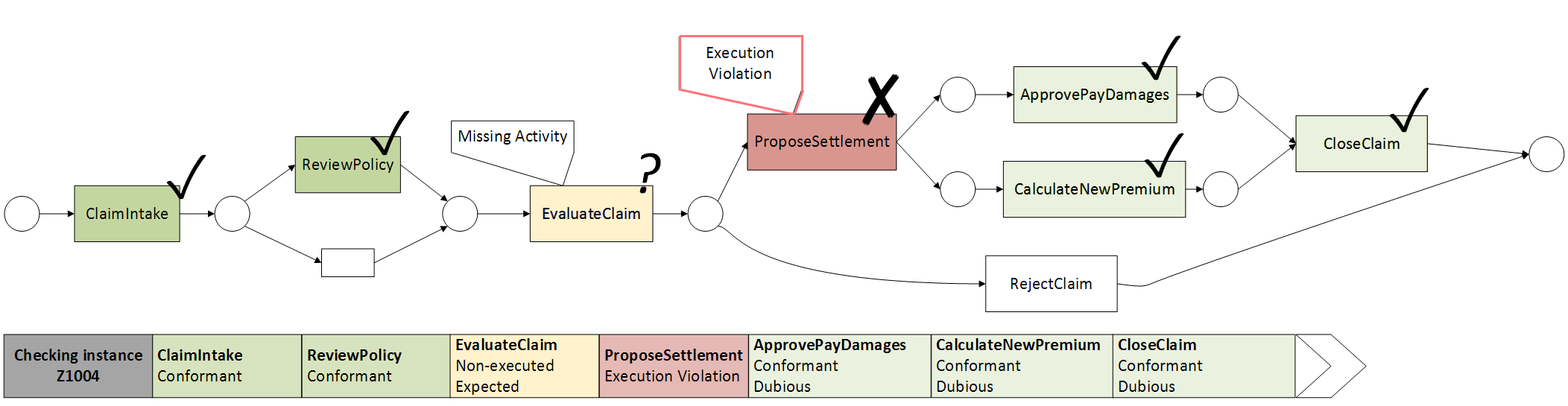
Note that various other analytical tasks exist. The following list enumerates a few examples:
- Rule based property verification of compliance checking. E.g. in an audit context: verifying if the four-eyes principle was applied correctly.
- Taking into account additional data, other than case identifiers, activity names and times. For instance by incorporating information about the workers having executed the tasks.
- Combining Process Mining with Social Analytics, for instance to derive social networks explaining how people work together.
- Combining Process Discovery with simulation techniques to iterate on “what if”-experiments and to predict the impact of applying a change in the process.
- Using Process Discovery techniques to perform customer journey mapping, or identifying visitor flows on websites.
Techniques also exist to support decision makers in predictive analytics. One particular area of interest has been the prediction of remaining process instance durations by learning patterns from historical data. Other approaches combine Process Mining with more traditional Data Mining techniques, which will be described further in the next section.
Integrating Process and Data Analytics: Closing the Loop
The main difference between Business Process Analytics (including Process Mining) and Data Analytics lies in the notion that Business Process Analytics works on two levels of aggregation. At the bottom level, we find the various events relating to certain activities and other additional attributes. By sorting these events and grouping them based on a case identifier — as done by Process Discovery — it becomes possible to take a process-centric view on the data set at hand. Therefore, many Process Mining techniques have been mainly focusing on this process-centric view, while spending less time and effort to aim to produce event-granular information. Because of this aspect, it is strongly advisable for practitioners to adopt an integrated approach by combining process-centric techniques with other Data Analytics.
To show how this works, consider the case of a process manager trying to apply Process Discovery to explore a complex and flexible business process. Workers are given many degrees of freedom to execute particular tasks, with very little imposed rules on how activities should be ordered. Such processes contain a high amount of variability, which leads Process Discovery techniques to extract so called “spaghetti models”. Clearly, this is an undesirable scenario. Although it is possible to filter out infrequent paths or activities, one might nevertheless prefer to get a good overview on how people execute their assigned work, without hiding low-frequent behavior which may signpost both problematic, rare cases, but perhaps also possible strategies to optimize the handling of certain tasks which have not become commonplace yet. Note that this is an important issue to keep in mind for any analytics task: extracting high-frequent patterns is crucial to get a good overview and derive main findings, but even more important is to analyze data sets based on the impact of patterns — meaning the low frequent patterns can nevertheless uncover crucial knowledge.
Clustering techniques exist to untangle spaghetti models into multiple smaller models, which all capture a set of behavior and are more understandable. As such, the complex event log with interwoven behavior can be decomposed into smaller, more comprehensible logs with associated discovered process models. After creating a set of clusters, it is possible to analyze these further and to derive correlations between the cluster an instance was placed in and its characteristics. For example, it is worthwhile to examine whether the discovered clusters exhibit significantly different average run times. Since it is now possible to label each process instance based on the clustering, we can also apply predictive analytics in order to construct a predictive classification model for new, future process instances, based on the attributes of the process when it is created. A decision tree can be extracted, for instance, which allows to predict the cluster a particular instance will match with most closely and as such derive expected running time, activity path followed, and other predictive information. Decision makers can then apply this information to organize an efficient division of workload.
By combining predictive analytics with Business Process Analytics, it is possible to come “full circle” when performing analytical tasks in a business process context. Note that the scope of applications is not only limited to the example described above. Similar techniques have also been applied, for example, to:
- Extract the criteria that determine how a process model will branch in a choice point.
- Combine process instance clustering with text mining.
- Suggest the optimal route for a process to follow during its execution.
- Recommend optimal workers to execute a certain task.
Conclusion
In this article, we have set out to provide a concise but thorough overview of state of the art Business Process Analytics techniques, ranging from Business Intelligence reporting tools to Process Mining techniques and a combined approach, which merges Business Process Analytics with Data Mining, thus narrowing the gap between traditional predictive analytics and data originating from process-aware support systems. As a closing note, we draw attention to the fact that this integrated approach does not only allow practitioners and analysts to “close the loop” regarding the set of techniques being applied (Business Process Analytics, Process Mining and Data Mining), but also enables to actively integrate continuous analytics within all phases of the BPM lifecycle. This contrary to being limited to a post-hoc exploratory investigation based on historical, logged data. As such, process improvement truly becomes an on-going effort, allowing process owners to implement improvements in a rapid and timely fashion, instead of relying on untimely reporting-analysis-redesign cycles.
For further reading on the techniques and concepts mentioned in this article, we refer to:
- W. M. P. van der Aalst, Process Mining: Discovery, Conformance and Enhancement of Business Processes, Springer Verlag, 2011.
- W. M. P. van der Aalst, A. J. M. M. Weijters, L. Maruster, Workflow mining: discovering process models from event logs, IEEE Transactions on Knowledge and Data Engineering, 16(9), 1128–1142, 2004.
- J. De Weerdt, S. vanden Broucke, J. Vanthienen, Baesens, B, Active trace clustering for improved process discovery, IEEE Transactions on Knowledge and Data Engineering, e-pub, 2013.
- A. Rozinat, W. M. P. van der Aalst, Decision Mining in ProM, Business Process Management 2006: 420-425, 2006.
- J. De Weerdt, S. vanden Broucke, J. Vanthienen, B. Baesens, Leveraging process discovery with trace clustering and text mining for intelligent analysis of incident management processes, Congress on Evolutionary Computation (CEC), 2012.
- M. Pesic, H. Schonenberg, W. M. P. van der Aalst, DECLARE: Full Support for Loosely-Structured Processes, Enterprise Distributed Object Computing Conference, 2007.
- A. Kim, J. Obregon, J. Y. Jung, Constructing Decision Trees from Process Logs for Performer Recommendation, DeMiMop’13 workshop of the BPM 2013 conference, 2013.