By: Bart Baesens, Seppe vanden Broucke
This QA first appeared in Data Science Briefings, the DataMiningApps newsletter as a “Free Tweet Consulting Experience” — where we answer a data science or analytics question of 140 characters maximum. Also want to submit your question? Just Tweet us @DataMiningApps. Want to remain anonymous? Then send us a direct message and we’ll keep all your details private. Subscribe now for free if you want to be the first to receive our articles and stay up to data on data science news, or follow us @DataMiningApps.
You asked: What is meant by denormalizing data for analytics?
Our answer:
The application of analytics typically requires or presumes the data to be presented in a single table containing and representing all the data in some structured way. A structured data table allows straightforward processing and analysis. Typically, the rows of a data table represent the basic entities to which the analysis applies; e.g., customers, transactions, firms, claims, cases.. The rows are also referred to as instances, records, observations, or lines. The columns in the data table contain information about the basic entities. Plenty of synonyms are used to denote the columns of the data table, such as (explanatory) variables, inputs, fields, characteristics, attributes, indicators, and features, among others.
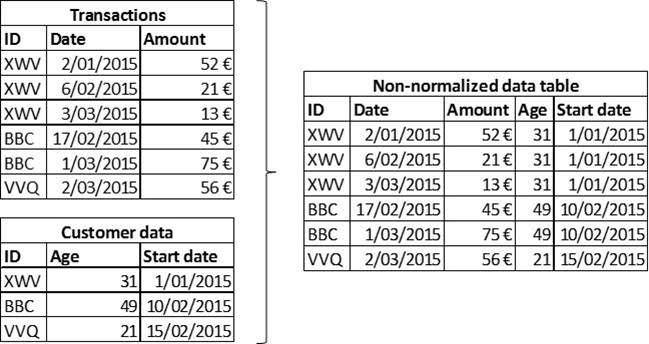
Several normalized source data tables have to be merged in order to construct the aggregated, denormalized data table. Merging tables involves selecting information from different tables related to an individual entity, and copying it to the aggregated data table. The individual entity can be recognized and selected in the different tables by making use of (primary) keys, which are attributes that have specifically been included in the table to allow identifying and relating observations from different source tables pertaining to the same entity. Figure 1 illustrates the process of merging two tables, i.e. transaction data and customer data, into a single non-normalized data table by making use of the key attribute ID which allows connecting observations in the transactions table with observations in the customer table. The same approach can be followed to merge as many tables as required, but clearly the more tables are merged, the more duplicate data might be included in the resulting table. It is crucial that no errors are introduced during this process, so some checks should be applied to control the resulting table and to make sure that all information is correctly integrated.