
Contributed by: Bart Baesens, Seppe vanden Broucke, Wilfried Lemahieu
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
In this column, we elaborate on the concept of data quality. It is based on our upcoming book Principles of Database Management, The Practical Guide to Storing, Managing and Analyzing Big and Small Data, see www.pdbmbook.com for more details.
Many organizations nowadays are struggling with the quality of their data. Data quality (DQ) problems can arise in various ways. Common causes of bad data quality are:
- Multiple data sources: multiple sources with the same data may produce duplicates; a problem of consistency.
- Limited computing resources: lack of sufficient computing resources and/or digitalization may limit the accessibility of relevant data; a problem of accessibility.
- Changing data needs: data requirements change on an ongoing basis due to new company strategies or the introduction of new technologies; a problem of relevance.
- Different processes using and updating the same data; a problem of consistency.
These causes of DQ problems have always existed to a certain extent, since the beginning of the digital era. However, initially, most data processing applications and database systems existed in relative isolation, as so-called silos. This was far from an ideal situation from a company-wide data sharing perspective, but at least the producers and consumers of the data were largely the same people or belonged to the same department or business unit. One was mostly aware of which DQ issues existed with one’s own data and people would often deal with them in an ad-hoc manner, based on familiarity with the data. However, with the advent of business process integration, company-wide data sharing and using data from various operational systems for strategic decision making, the data producers and consumers have been largely decoupled. Therefore, people responsible for entering the data are not fully aware of the data quality requirements of the people using the data, or of the different business processes in which the data is used. Moreover, different tasks using the same data may have very distinct DQ requirements.
Due to data quality problems we just introduced, organizations are increasingly implementing company-wide data governance initiatives to measure, monitor and improve the data quality dimensions that are relevant to them. To manage and safeguard data quality, a data governance culture should be put in place assigning clear roles and responsibilities. The aim of data governance is to set up a company-wide controlled and supported approach towards data quality accompanied by data quality management processes. The core idea is to manage data as an asset rather than a liability, and adopt a proactive attitude towards data quality. To succeed, it should be a key element of a company’s corporate governance and supported by senior management.
Different frameworks have been introduced for data quality management and data quality improvement. Some are rooted in quality management while others focus explicitly on data quality. Another category of frameworks focuses on the maturity of data quality management processes. They aim at assessing the maturity level of DQ management to understand best practices in mature organizations and identify areas for improvement. Popular examples of such frameworks include: Total Data Quality Management (TDQM), Capability Maturity Model Integration (CMMI), Control Objectives for Information and Related Technology (CobiT), Information Technology Infrastructure Library (ITIL) and Six Sigma.
As an example, the TDQM framework is illustrated in the figure below.
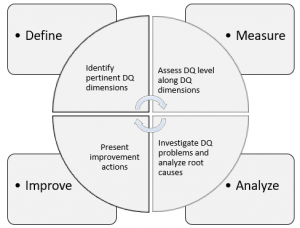
Wang R.Y., A Product Perspective on Total Data Quality Management, Communications of the ACM, Volume 41, Number 2, 1998.
A TDQM cycle consists of four steps: Define, Measure, Analyze, and Improve, which are performed iteratively. The Define step identifies the pertinent data quality dimensions. These can then be quantified using metrics in the measure step. Some example metrics are: the percentage of customer records with an incorrect address (accuracy), the percentage of customer records with missing birth date (completeness), or an indicator specifying when customer data was last updated (timeliness). The analyze step tries to identify the root cause of the diagnosed data quality problems. These can then be remedied in the improve step. Example actions could be: automatic and periodic verification of customer addresses, the addition of a constraint that makes the birth date a mandatory data field, and the generation of alerts when customer data has not been updated during the previous 6 months.
If actual data quality improvement is not an option in the short term for reasons of technical constraints or strategic priorities, it is sometimes a partial solution to annotate the data with explicit information about its quality. Such data quality metadata can be stored in the catalog, possibly with other metadata. In this way, the DQ issues are not resolved, but at least data consumers across the organization are aware of them and can take the necessary precautions as part of their task execution. For example, credit risk models could incorporate an additional risk factor to account for uncertainty in the data, derived from data quality metadata. Unfortunately, many companies still ignore data quality problems because of a lack of perceived added value. Hence, many data governance efforts (if any) are mostly reactive and ad-hoc, only addressing the data quality issues as they occur.
For more information, we are happy to refer to our upcoming book, Principles of Database Management, see www.pdbmbook.com.