
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
Contributed by: Bart Baesens, Wilfried Lemahieu, Seppe vanden Broucke
Introduction
As companies often end up with many information systems and databases over time, the aspect of data integration becomes increasingly important to consolidate a company’s data to provide one, unified view to analytics applications and users. Data integration aims at providing a unified and consistent view of all enterprise wide data. The data itself may be heterogeneous and reside in difference resources (XML files, relational databases, etc.). The desired extent of data integration will depend upon the required Quality of Service characteristics. The goal of data integration is to logically (and sometimes also physically) unify different data sources, or data silos, to provide a single unified view which is as correct, complete, and consistent as possible.
In this article, we discuss the following basic data integration patterns: data consolidation, data federation, and data propagation. It is based upon our book: Principles of Database Management: The Practical Guide to Storing, Managing and Analyzing Big and Small Data, see www.pdbmbook.com.
Data Consolidation: Extract, Transform, Load (ETL)
Data consolidation captures data from multiple, heterogeneous source systems and integrates it into a single persistent store (e.g., a data warehouse). This is typically accomplished using extract, transform and load (ETL) routines (Figure 2):
- Extract data from heterogeneous data sources
- Transform the data to satisfy business needs
- Load the transformed data into a target system
This approach with an ETL process feeding a store with consolidated data is very suitable to deal with massive amounts of data and prepare them for analytics. There is room for extensive transformation, involving data restructuring, reconciliation, cleansing, aggregation and enrichment steps. Therefore, this pattern has a positive impact on many data quality dimensions such as completeness, consistency, and interpretability. Another important advantage is that it caters for not only present information, but also historical data, since a changed business state does not result in updates to the data, but in additions of new data.
On the downside, the ETL process typically induces a certain measure of latency, so the timeliness dimension may suffer, with the data being slightly out of date. Consolidation also requires a physical target. This allows for analytics workloads to be removed from the original data sources. That, with the fact that the data are already formatted and structured up front to suit the analytical needs, guarantees acceptable performance levels.
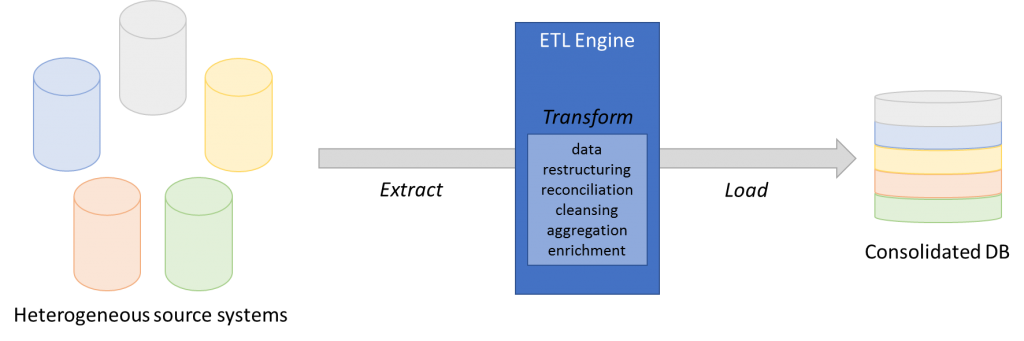
Figure 2: Extract, Transform, Load (ETL)
Data lakes can also be an implementation of the consolidation pattern. However, in contrast to a data warehouse, the data is mostly consolidated in the native format it had in the source systems, with little transformation or cleansing. Therefore, the positive impact on the respective data quality dimensions will be limited compared to a data warehouse, but this is often less of an issue for the big data types typically stored in data lakes, where the formal structure is much more volatile or even completely absent.
Data Federation: Enterprise Information Integration (EII)
Data federation also aims a providing a unified view over one or more data sources. Instead of capturing and integrating the data in one consolidated store, it typically follows a pull approach where data is pulled from the underlying source systems on an on-demand basis. Enterprise Information Integration (EII) is an example of a data federation technology (Figure 3). EII can be implemented by realizing a virtual business view on the dispersed underlying data sources. The view serves as a universal data access layer. The data sources’ internals are isolated from the outside world by means of wrappers. In this way, the virtual view shields the applications and processes from the complexities of retrieving the needed data from multiple locations, with different semantics, formats, and interfaces. A federation strategy enables real-time access to current data, which was not the case for a data consolidation strategy.
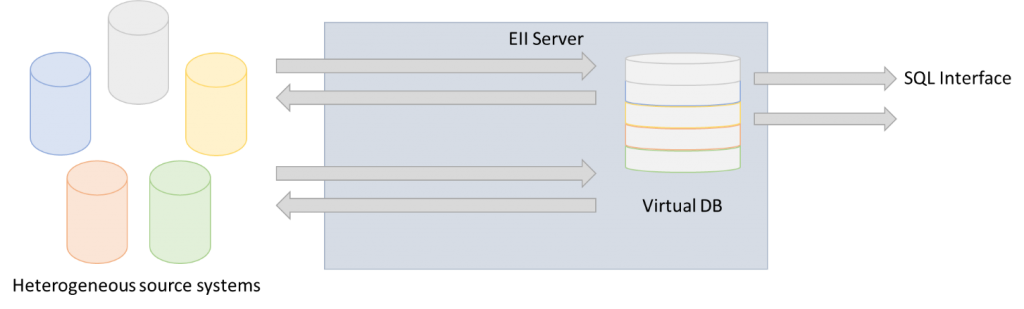
Figure 3: Enterprise Information Integration (EII)
Queries performed on the business view will be translated into queries on the underlying data sources. The returned results will typically be rather small because the real-time characteristic is prohibitive to larger data sets. For the same reason, only limited transformation and cleansing capabilities are possible. Many EII technologies are read-only, but some also support update operations on the business view, which are then applied to the underlying data stores.
Data Federation and EII can be beneficial as it leaves data in place. One important disadvantage to remember is the overall worse performance of EII. Since queries performed on the business view must be translated to underlying data sources, a performance hit is unavoidable. Note that EII solutions are limited in the number of transformation and cleansing they can perform on query result sets.
Data Propagation: Enterprise Application Integration (EAI)
The propagation pattern corresponds to the synchronous or asynchronous propagation of updates or, more generally, events in a source system to a target system. Most implementations provide some measure of guaranteed delivery of the update or event notification to the target system. In fact, the data propagation pattern can be applied at two levels in a system architecture. It can be applied in the interaction between two applications or in the synchronization between two data stores. In an application interaction context, we speak of Enterprise Application Integration (EAI). In a data store context, we speak of Enterprise Data Replication (EDR).
The idea of EAI is that an event in the source application requires some processing within the target application. For example, if an order is received in an order handling application, this may trigger the creation of an invoice in the invoicing application. The event in the source system (an order is received) is notified to the target system to trigger some processing there (the creation of an invoice). There exist many distinct EAI technologies to realize this triggering, ranging from web services, .NET or Java interfaces, messaging middleware, etc. However, besides the triggering of some processing within the target application, such exchange nearly always involves small amounts of data being propagated from the source to the target application as well.
The data propagation in EAI may occur synchronously, so the message is sent, along with the data, at the moment the event occurs in the source system. The target system may respond immediately, but the message may also be queued before being processed, resulting in asynchronous interaction. The advantage of an asynchronous approach is less interdependence between the respective systems, but the downside is a certain latency in responding to an event and processing the data that goes along with it.
Data propagation with EAI is usually employed for operational business transaction processing across multiple systems that act upon one another’s events and therefore require (partially) the same data.
Data Propagation: Enterprise Data Replication (EDR)
The propagation pattern can also be applied at the level of the interaction between two data stores. In that case, we speak of Enterprise Data Replication (EDR). Here, the events in the source system explicitly pertain to update events in the data store. Replication means copying the updates in the source system in (near) real time to a target data store which serves as an exact replica. EDR has been traditionally adopted for load balancing, ensuring high availability, recovery but not data integration as such. However, recently it is being used more often for (operational) BI and to offload data from the source systems onto a separate data store, which is an exact replica. In this way, analytics can be performed on real-time operational data, without burdening the original operational source systems with additional workload.
The boundary between EDR and ETL is not always very sharp. The event paradigm and real-time aspect of EDR can be combined with the consolidation and transformation elements of ETL, resulting in so-called near real-time ETL.
Changed Data Capture (CDC), Near Real Time ETL and Event Processing
Changed Data Capture (CDC) can detect update events in the source data store, and trigger the ETL process based on these updates. In this way, a ‘push’ model to ETL is supported: the ETL process is triggered by any significant change in the underlying data store(s). This is in contrast with traditional ETL, where data extraction occurs on scheduled time intervals or in periods with low system workload, but without considering actual changes in the source data.
This approach is often technically more complex, and its feasibility depends to a certain extent on the characteristics and openness of the source systems. On the other hand, it has several advantages. A first advantage is a real-time capability; changes in the source systems can be detected and propagated as they occur, rather than them being propagated with a certain latency, according to the fixed schedule of the ETL process. The approach may also reduce network load since only data are transferred that have actually changed.
Finally, it is important to note that the event notification pattern can also play other roles in a data processing setting. Relevant events can be notified to multiple components or applications that can act upon the event and trigger some processing, e.g., by means of EAI technology. Also, the events generated in this context are more and more also the focus of analytics techniques, especially in Business Activity Monitoring and process analytics. Complex event processing (CEP) refers to a series of analytics techniques that do not focus on individual events, but rather on the interrelationships between events and patterns within so-called event clouds. For example, a suddenly changing pattern in purchases made with a certain credit card may be an indication of fraud. Event notifications can be buffered, and in this way acted upon asynchronously, or they can be processed in real time.
Data Virtualization
Data virtualization is a more recent approach to data integration and management that also aims to offer a unified data view for applications to retrieve and manipulate data without necessarily knowing where the data is stored physically or how it is structured and formatted at the sources. Data virtualization builds upon the basic data integration patterns discussed previously, but also isolates applications and users from the actual (combinations of) integration patterns used.
The technologies underlying data virtualization solutions vary widely from vendor to vendor, but they often avoid data consolidation techniques such as ETL: the source data remains in place, and real-time access is provided to the source systems of the data. This approach hence seems familiar to data federation, but an important difference of data virtualization is that, contrary to a federated database as offered by basic EII, virtualization does not impose a single data model on top of the heterogeneous data sources. Virtual views on the data can be defined at will and can be mapped top-down onto relational and non-relational data sources. Data virtualization systems can apply various transformations before offering the data to its consumers. Hence, they combine the best features of traditional data consolidation. To guarantee sufficient performance, virtual views are cached transparently, and query optimization techniques are applied. However, for very large volumes of data, the combination of consolidation and ETL may still be the most efficient approach performance wise. There, virtualization techniques can provide a unified view of the consolidated data and other data sources, e.g., to integrate historical data with real-time data.
The pattern of virtualization is often linked to the concept of Data as a Service (DaaS), in which data services are offered as part of the overall Service Oriented Architecture (SOA). The data services can be invoked by different applications and business processes, which are isolated from how the data services are realized regarding location, data storage, and data integration technology.
Conclusion
To summarize this article, in many real-life contexts, a data integration exercise is an ongoing initiative within an organization, and will often combine many integration strategies and approaches.
For more information, we are happy to refer to our book, Principles of Database Management: The Practical Guide to Storing, Managing and Analyzing Big and Small Data, see www.pdbmbook.com.