
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
Contributed by: Bart Baesens, Seppe vanden Broucke
Recommender systems have been defined by Ricci et al [1] already in 2011 as software tools and techniques providing suggestions for items to be of use to a user. Two key concepts here are items and users. As a simple example think of items as books on Amazon and users as readers.
Recommender systems serve various other purposes in terms of business value. First, they facilitate customer retention and deepening of customer relationships by offering well-targeted products or services to your existing customer base. Obviously, this will result in increased sales. X-selling is a popular aim of recommender systems. The aim is to change the intended purchase behavior of a customer using recommendation patterns learned from data. This can be done in three possible ways: up-selling, cross-selling or down-selling. The idea of up-selling is to sell more of a given product, usually at the time of purchase. Cross-selling aims at selling an additional product or service. Finally, down-selling means selling less of a product or service in order to maintain a sustainable, long-lasting customer relationship. From a business perspective, it is important to understand which products are often purchased together, so as to make good recommendations. Finally, recommender systems aim at increasing the so called hit, clickthrough or lookers to bookers rates.
A key element in building a recommender system is the rating matrix. A rating matrix is basically constructed by aggregating user interest data into a single user item score per user and item pair. The rows represent the users the columns represent the items. The rating then depends upon the observed interest, measured either implicitly or explicitly. It could be based on either unary feedback indicators, such as a click or no click, or a 5 star rating system as adopted by Amazon for example, where the rating is a number between 1 and 5. The rating can also be a combination of multiple feedback indicators, combining even explicit and implicit user interest
Collaborative filtering methods use the rating matrix to make a prediction. They are typically based on the k-nearest neighbor idea by considering either the k-most similar users or k-most similar items. User-user collaborative filtering calculates similarity between users, and items are proposed on the basis of the behavior of a user’s nearest neighbors. Item-item collaborative filtering calculates similarity between items and proposes items that are similar to those previously purchased by the customer. As said, both methods essentially embody a nearest-neighbor type of reasoning, either from the user perspective, or from the item perspective. In what follows, we discuss item-item collaborative filtering and motivate later why we prefer this above user-user collaborative filtering.
In item-item collaborative filtering, the idea is to apply the k-nearest neighbor idea, and look for similar items instead of similar users. The basic intuition says: items which were liked by the same users, will likely continue to be liked by the same users. So if Bart liked the Rocky movies, and users rate Rocky similar to The Karate Kid, then Bart will most likely like the Karate Kid as well.
Item-Item collaborative filtering proceeds along 2 steps. First, the item-item similarities are computed using a similarity measure such as the Pearson correlation, the cosine similarity, the adjusted cosine similarity or the Jaccard index. In case of M items, this implies the calculation of M*(M-1)/2 item similarities. In a next step, we recommend items similar to the items a user has shown interest in.
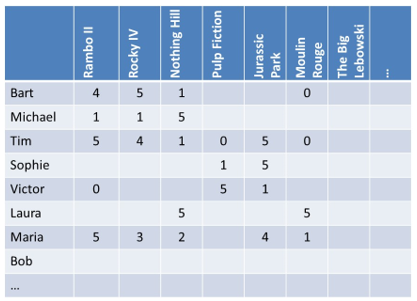
Let’s assume we start from the following rating matrix.
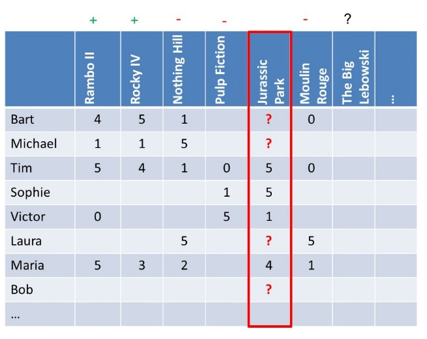
Let’s pick out the Jurassic Park movie first as you can see illustrated below. You can see that the ratings correlate pretty well with the Rambo II and Rocky IV movies, but less with Nothing Hill, Pulp Fiction and Moulin Rouge. Due to a lack of ratings the correlation with the Big Lebowski is unknown. We can do a similar analysis for the other movies.
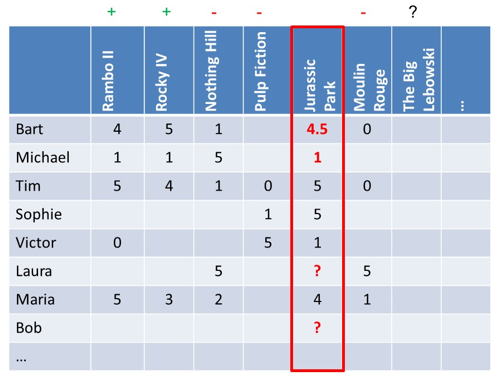
For the sake of simplicity, let’s assume we adopt a 2 nearest neighbor method. The two most similar items to Jurassic Park are Rambo II and Rocky IV. In other words, we can take the average of both the rating 4 assigned by Bart to Rambo II and rating 5 to Rocky IV and assign rating 4.5 to Jurassic Park. Hence, it makes sense to recommend Jurassic Park to Bart. For Michael, it makes no sense to recommend Jurassic Park as the predicted rating is 1. For Laura and Bob, we don’t have any data so cannot calculate a prediction. One fallback option could be to use the overall average rating for Jurassic Park, which is obviously not ideal. Below you can see the result.
A smarter way could to work with weights such that more similar items contribute more to the predicted rating as follows:
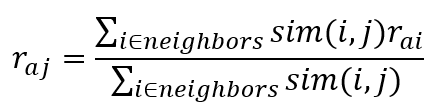
In the numerator, every rating of a neighbor is weighted by the similarity, which can again be the Pearson, cosine, adjusted cosine, or Jaccard similarity. We then normalise in the denominator by the sum of all item similarities. We can also adopt a variant to take into account possible rating bias:
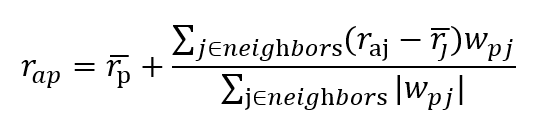
Note that a refers to the user, p the item to generate recommendations for, j the neighboring items of item p, hat{r_x}: average rating of item x and w_xy the similarity between items x and y. Many other options are available and worth experimenting with.
There are several scenarios where item-based collaborative filtering methods are preferred above user-based collaborative filtering. Consider a ratings data set where the number of users is significantly larger than the number of items. Hence, the computational complexity of methods that model item similarities is significantly lower than methods that model user similarities. For example, an online music store may have hundreds of millions of users with only tens of thousands of songs or items. Furthermore, note that according to research, item similarities are considered to be more stable than user similarities. The reason is that items are simpler whereas users typically have multiple tastes. More specifically, it is easier to find items with the same characteristics than it is to find users that like only items of a single category or genre. As an example, ratings on the movie “Saving Private Ryan” will probably be highly correlated with ratings on the movies “Pearl Harbour”, “Dunkirk”, “Midway”, and other war movies. However, on the contrary, users may like similar items but each also have their own-specific differences. For example, Bart may like war movies, but also wildlife documentaries, whereas Michael also likes war movies, but instead likes science fiction movies like Star Wars, which differentiates Michael from Bart. Item-item collaborative filtering is the approach adopted by Amazon.com who calculates the pair-wise item similarities in advance. Note that here the neighborhood is typically rather small because only items are considered which the user has rated. Finally, although deep learning methods have been suggested for building recommendation systems as well, a recent study of Dacrema et al. in the 2019 RecSys proceedings [2] seriously questions their added value when compared to a simple item-item collaborative filtering method we discussed in this article.
For more information, we are happy to refer to our newest BlueCourses course on Recommender Systems.
References
- Ricci F., Rokach L., Shapira B., Recommender Systems Handbook, Springer 2015.
- Dacrema M.F., Cremonesi P., Jannach D., Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches, Proceedings of the 13th ACM Conference on Recommender Systems (RecSys 2019), 2019.