
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
Contributed by: Manon Reusens.
Advances in AI have been all over the news lately with the newest text generation models like ChatGPT and Bard. However, applications of these models are not limited to just text. Transformers are also utilized in the domain of image generation (think of the Vision Transformer (ViT)). Moreover, the transformer model is now used in the field of audio generation and processing, a domain that is both versatile and full of potential for creating new and innovative applications.
So, what exactly is audio data? An audio wave is defined as the vibration of air when a sound is produced. The vibration propagates as a wave and can be depicted in both the time domain and the frequency domain. An audio signal in the time domain shows the wave that changes in amplitude (=magnitude of the wave expressed in dB) over time. In this domain, you do not have information on the frequency (= the pitch expressed in Hz). We plotted both in the Figure below using the Nutcracker of Tsjaikovsky as audio data (time domain on the left, frequency domain on the right):
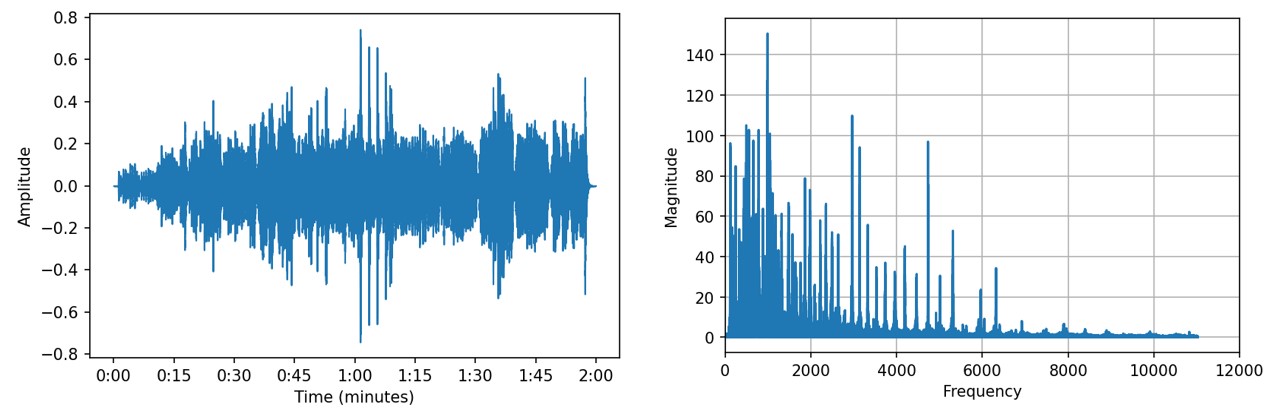
Going from a frequency plot to a vector representation might not be ideal as it can result in the loss of time-related information, such as the order of spoken words. A spectrogram offers a solution to this issue by converting audio data into an image format. This transformation from audio to an image makes it possible to tackle audio classification problems as image classification problems, with the spectrogram serving as input for a Convolutional Neural Network.
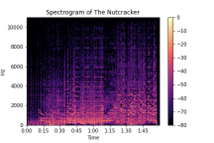
Audio represented in spectrogram
Now that you have a basic understanding of audio data, let’s dive a bit deeper into the latest advances in the field. In 2020, Facebook AI introduced Wav2Vec [1], followed by Wav2Vec 2.0 [2], a self-supervised learning model that uses the raw audio wave as input. The model consists of a convolutional network followed by a transformer and is pre-trained similarly to BERT (a large language model [3]), also by making out a proportion of the input and letting the model predict the masked-out part.
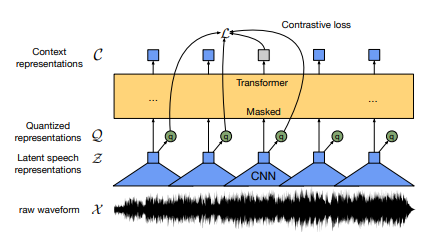
Architecture Wav2Vec 2.0 from [2]
Later, Wave2Vec was modified by using the log-Mel spectrogram instead of the raw wave as input [4]. This type of spectrogram is a spectrogram (as shown in figure 3) converted to the Mel scale (the range of frequencies humans can perceive). This improved computational and memory efficiency. Both models were trained for speech representations and can thus be finetuned for example for speech recognition tasks.
In the domain of music classification and generation, Google recently launched MusicLM, a model that can generate music from text [5]. The architecture of MusicLM consists of three different models to get vector representations of audio, which are then sequentially combined to achieve text-conditioned music generation. For a detailed explanation of the model, we refer you to the original paper. If you’d like to hear some of the audio output generated by MusicLM, you can check it out here.
In conclusion, the field of audio generation and processing shows great potential, and with advances in technology, the possibilities are endless.
References:
- [1] Baevski, A., Auli, M., & Mohamed, A. (2019). Effectiveness of self-supervised pre-training for speech recognition. arXiv preprint arXiv:1911.03912.
- [2] Baevski, A., Zhou, Y., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems, 33, 12449-12460.
- [3] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- [4] Tjandra, A., Choudhury, D. G., Zhang, F., Singh, K., Conneau, A., Baevski, A., … & Auli, M. (2022, May). Improved language identification through cross-lingual self-supervised learning. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6877-6881). IEEE.
- [5] Agostinelli, A., Denk, T. I., Borsos, Z., Engel, J., Verzetti, M., Caillon, A., … & Frank, C. (2023). MusicLM: Generating Music From Text. arXiv preprint arXiv:2301.11325.