
By: Bart Baesens, Seppe vanden Broucke
This QA first appeared in Data Science Briefings, the DataMiningApps newsletter as a “Free Tweet Consulting Experience” — where we answer a data science or analytics question of 140 characters maximum. Also want to submit your question? Just Tweet us @DataMiningApps. Want to remain anonymous? Then send us a direct message and we’ll keep all your details private. Subscribe now for free if you want to be the first to receive our articles and stay up to data on data science news, or follow us @DataMiningApps.
You asked: About your presentation on social network analytics on the DataMiningApps Youtube channel: can you work out a simple example? Besides fraud, any other successful applications of SNA?
Our answer:
A way how we can incorporate social network effects in a predictive model is by means of featurization. This means we create features out of the network characteristics and add them to our data set together with the non-network variables. We can then analyze this data set using any predictive technique (e.g. logistic regression, neural network, random forest).
Consider the following network as an example:
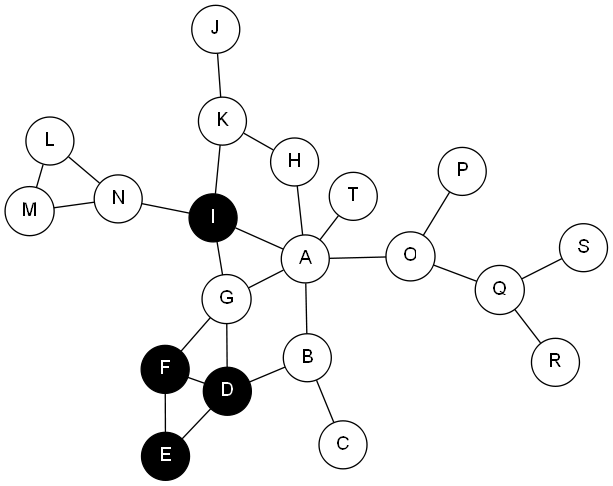
The nodes A, B, … represent customers (e.g. retail customers or companies). Filled in nodes represent fraudulent customers and white nodes non-fraudulent customers. We can now create features such as:
- Total degree: total number of links of a node
- Fraud/Legit degree: total number of links to fraudulent/legit nodes of a node
- Mode link: indicates whether most of the neighbors are fraudsters or non-fraudsters
- Count fraud: counts the number of fraudsters amongst the neighbors
- Count non-fraud: counts the number of non-fraudsters amongst the neighbors
- Binary fraud: indicates whether there is a fraudster amongst the neighbors
- Binary non-fraud: indicates whether there is a non-fraudster amongst the neighbors
These are just a few examples of features we can create from the network. In our fraud analytics book, we provide lots of other examples. Obviously, many of them will be correlated so it is important to perform variable selection during analytical model development. The features are also typically defined in close collaboration with the business expert.
| Node | A | B | C | D | E | F | G | H | I | J |
| Total Degree | 6 | 3 | 1 | 4 | 2 | 3 | 4 | 2 | 4 | 1 |
| Fraud Degree | 1 | 1 | 0 | 2 | 2 | 2 | 3 | 0 | 0 | 0 |
| Legit Degree | 5 | 2 | 1 | 2 | 0 | 1 | 1 | 2 | 4 | 1 |
| Mode link | NF | NF | NF | NF/F | F | F | F | NF | NF | NF |
| Count fraud | 1 | 1 | 0 | 2 | 2 | 2 | 3 | 0 | 0 | 0 |
| Count non-fraud | 5 | 2 | 1 | 2 | 0 | 1 | 1 | 2 | 4 | 1 |
| Binary fraud | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| Binary non-fraud | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
These network features can now be complemented with local characteristics of each of the nodes. Just think about socio-demographic characteristics such as age, income, employment status, etc. The resulting data set can then be fed to a plain vanilla analytical technique such as a logistic or random forest model to build a predictive model for fraud detection.
About your second question: we found social network effects to have a huge impact in fraud analytics but also in churn prediction in Telco. In our previous research, we built social networks based on call detail records (CDR) and then featurized those. The resulting analytical models clearly indicated the impact of social network effects (up to > 5% performance gain in terms of area under the ROC curve).